所有的 ORM 关联数据读取中都存在N+1的问题,新手很容易踩到坑。进而导致系统变慢,然后拖垮整个系统。既然所有orm都会有这种问题,那我们来看看在Django中是如何解决的。
什么是N+1 在一个有多条返回记录的单表查询中,每条记录又独立查询了其对应关联表的数据,这就是N+1。
用通俗示例来讲它可能更容易被理解,比如我查询5篇文章,每篇文章又查询了它对应的分类名称,查询的5篇文章对应了1条sql,其中的每篇文章又查询了对应的分类名称这又是5条sql,加起来用了6条sql才达到想要的结果,这就是N+1。
大概用到的sql如下:
1 2 3 4 5 6 7 8 9 10 select id, title, content, category_id from article;select id, title from category where id = 1 ;select id, title from category where id = 2 ;select id, title from category where id = 2 ;select id, title from category where id = 2 ;select id, title from category where id = 3 ;
如何解决N+1 其实也很简单,原生sql来讲直接用连接查询就可以了,还以上面为例,我们改造下sql,就能直接拿到每篇文章对应的分类名了。
1 2 select a.id, a.title, a.content, a.category_id, c.id, c.title from article a inner join category c on a.category_id= c.id;
django中如何解决N+1问题django中提供了两个非常重要的查询方法select_related和prefetch_related方法,看看如何使用它们避免不必要的数据库查询。高手过招,只差分毫。专业和业余之前的区别就在细节的处理上。为了让大家更直观地看到这两个方法的作用,我们将安装使用django-debug-toolbar。
第一步:pip install django-debug-toolbar
第二步:打开项目文件夹settings.py 文件, 把”debug_toolbar“加到INSTALLED_APP里去。
第三步: 打开项目文件夹里的urls.py, 把debug_toolbar的urls加进去。
1 2 3 4 5 6 7 8 9 from django.conf import settingsfrom django.urls import include, path if settings.DEBUG: import debug_toolbar urlpatterns = [ path('__debug__/' , include(debug_toolbar.urls)), ] + urlpatterns
第四步: 在settings.py里添加中间件
1 2 3 4 5 6 7 8 9 10 11 MIDDLEWARE = [ 'debug_toolbar.middleware.DebugToolbarMiddleware' , ] 第五步: 在settings.py设置本地IP, debug_toolbar只能在localhost本地测试环境下运行。 INTERNAL_IPS = [ '127.0.0.1' , ]
以上边完成了django-debug-toolbar的安装配置
模型准备 我这里准备了5张表来说明及解决这个问题,让大家更清晰明了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 from django.db import modelsclass City (models.Model): """城市""" title = models.CharField(verbose_name="城市名" , max_length=50 ) def __str__ (self ): return self.title class Meta : verbose_name = "城市" verbose_name_plural = verbose_name class UserProfile (models.Model): username = models.CharField(max_length=12 , verbose_name="用户名" ) gender = models.SmallIntegerField(verbose_name="性别" , choices=((1 , "男" ), (0 , "女" ))) city = models.ForeignKey("City" , verbose_name="所在城市" , on_delete=models.CASCADE, related_name="city_users" , blank=True , null=True ) def __str__ (self ): return self.username class Meta : verbose_name = "用户" verbose_name_plural = verbose_name class Category (models.Model): """文章分类""" title = models.CharField(max_length=50 , verbose_name="标题" ) def __str__ (self ): return self.title class Meta : verbose_name = "文章分类" verbose_name_plural = verbose_name class Tag (models.Model): """文章标签""" title = models.CharField(max_length=50 , verbose_name="标题" ) def __str__ (self ): return self.title class Meta : verbose_name = "文章标签" verbose_name_plural = verbose_name class Article (models.Model): """文章""" title = models.CharField(max_length=50 , verbose_name="标题" ) desc = models.CharField(max_length=255 , verbose_name="简介" ) category = models.ForeignKey("Category" , verbose_name="分类" , on_delete=models.CASCADE, related_name="cat_articles" ) tags = models.ManyToManyField("Tag" , verbose_name="标签" , related_name="tag_articles" ) author = models.ForeignKey("UserProfile" , verbose_name="作者" , on_delete=models.CASCADE, related_name="author_articles" , null=True , blank=True ) def __str__ (self ): return self.title class Meta : verbose_name = "文章" verbose_name_plural = verbose_name
视图及模板准备 视图 1 2 3 4 def list (request, *args, **kwargs ): """文章列表""" articles = Article.objects.all () return render(request, 'list.html' , {"articles" :articles})
模板 好久没写html且一直做前后端分离的原生html标签都陌生了,用IDE编写table提示border和cellpadding都是已经废弃的属性了,但是不影响我们测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <title > 文章列表</title > </head > <body > <h1 > 文章列表</h1 > <table border ="1" cellpadding ="10" > <tr > <th > 文章标题</th > <th > 分类名</th > <th > 文章标签</th > </tr > {% for article in articles %} <tr > <td > {{ article.title }}</td > <td > {{ article.category.title }}</td > <td > {% for tag in article.tags.all %} {{ tag.title }}, {% endfor %}</td > </tr > {% endfor %} </table > </body > </html >
前端效果
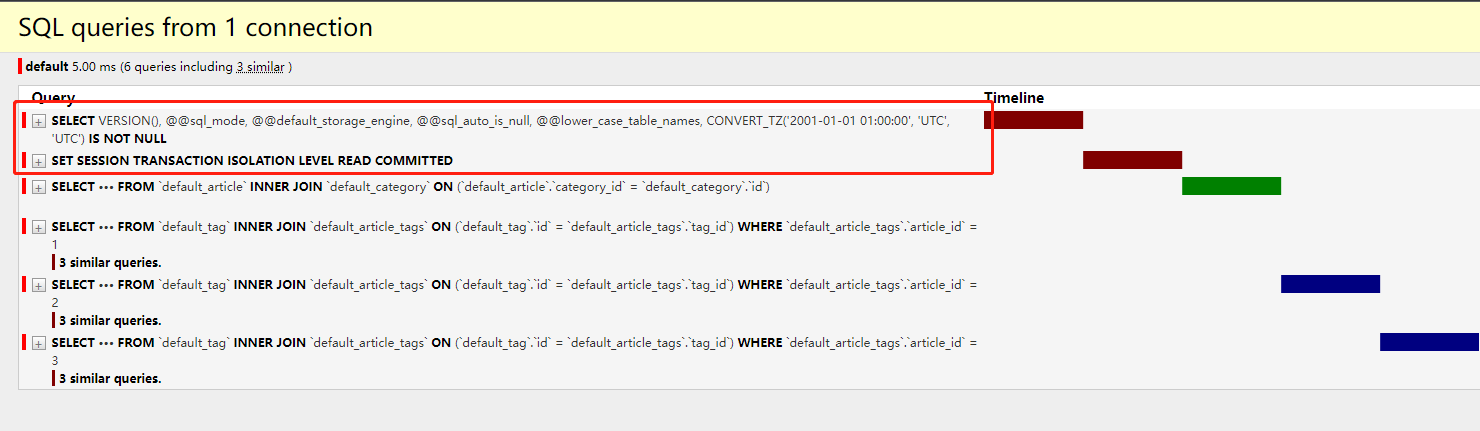
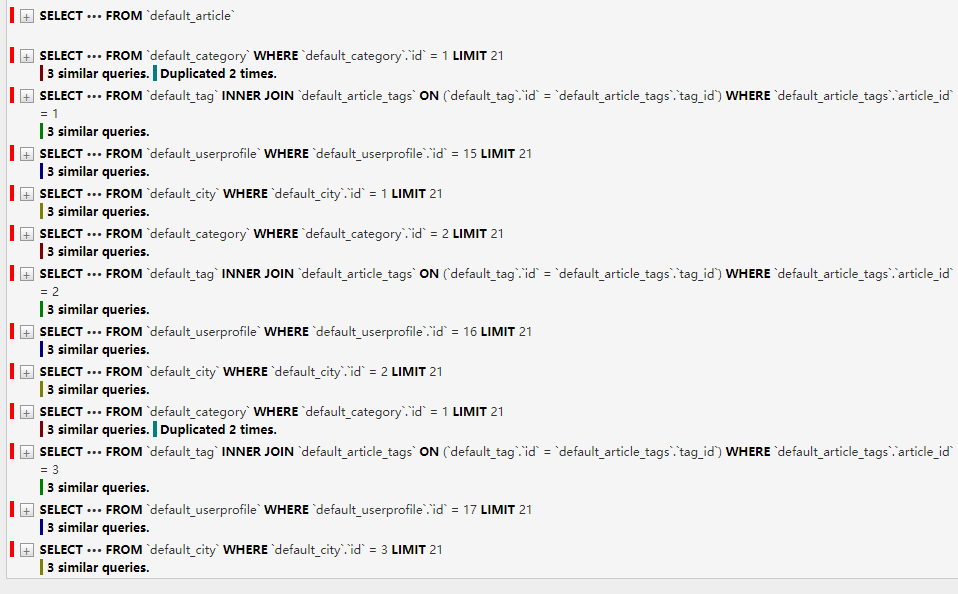
如图详细列出了该页面有8条sql执行,6条相似的,2条重复的,总用用时3ms,为了方便我们将以上sql一一拿出来作解释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 -- 设置当前会话事务隔离界别为READ COMMITTED(读已提交),熟悉的同学知道该级别仅能解决脏读问题,不能解决不可重复读和幻读的问题 SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED -- 查询所有文章信息 SELECT `default_article`.`id`, `default_article`.`title`, `default_article`.`desc`, `default_article`.`category_id`, `default_article`.`author_id` FROM `default_article` -- 查询文章分类id为1的分类信息 SELECT `default_category`.`id`, `default_category`.`title` FROM `default_category` WHERE `default_category`.`id` = 1 LIMIT 21 -- 查询id为1的文章对应的所有标签信息 SELECT `default_tag`.`id`, `default_tag`.`title` FROM `default_tag` INNER JOIN `default_article_tags` ON (`default_tag`.`id` = `default_article_tags`.`tag_id`) WHERE `default_article_tags`.`article_id` = 1 -- 查询文章分类id为2的分类信息 SELECT `default_category`.`id`, `default_category`.`title` FROM `default_category` WHERE `default_category`.`id` = 2 LIMIT 21 -- 查询id为2的文章对应的所有标签信息 SELECT `default_tag`.`id`, `default_tag`.`title` FROM `default_tag` INNER JOIN `default_article_tags` ON (`default_tag`.`id` = `default_article_tags`.`tag_id`) WHERE `default_article_tags`.`article_id` = 2 -- 查询文章分类id为1的分类信息 SELECT `default_category`.`id`, `default_category`.`title` FROM `default_category` WHERE `default_category`.`id` = 1 LIMIT 21 -- 查询id为3的文章对应的所有标签信息 SELECT `default_tag`.`id`, `default_tag`.`title` FROM `default_tag` INNER JOIN `default_article_tags` ON (`default_tag`.`id` = `default_article_tags`.`tag_id`) WHERE `default_article_tags`.`article_id` = 3
这样会导致线性的SQL查询,如果对象数量n太多,每个对象中有k个外键字段的话,就会导致n*k+1次SQL查询。在本例中,因为有3个article对象就导致了7次SQL查询:3*2+1。
我们改造下view
1 2 3 4 def list (request, *args, **kwargs ): """文章列表""" articles = Article.objects.select_related("category" ).all () return render(request, 'list.html' , {"articles" :articles})
再次执行
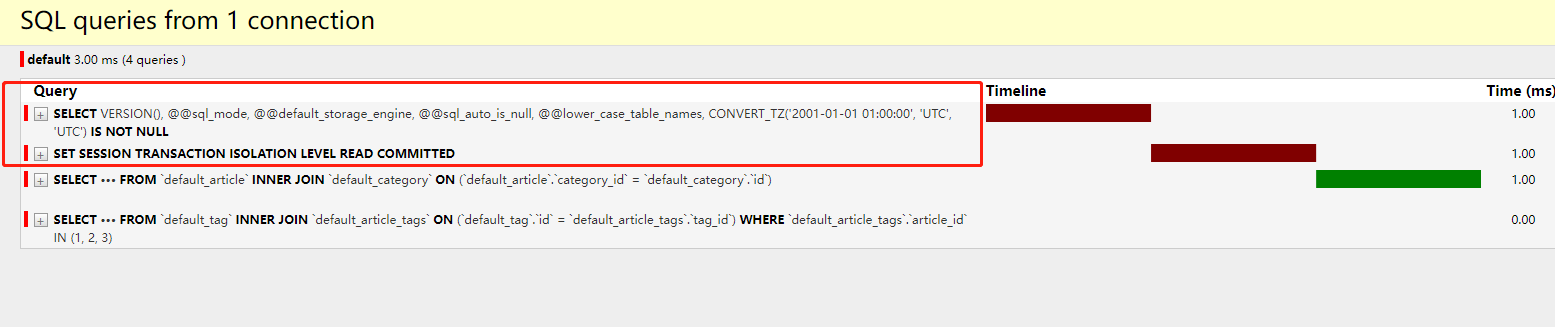
忽略前两条系统默认执行的,现在我们的sql由7条变为了4条,解决了一个外联字段n+1的问题。后3条可以看出来还是查询每篇文章对应标签信息的sql语句,我们主要看第一条sql语句变为了什么,导致少了3条sql还能达到一样的效果。
原始首条查询所有文章的语句
1 2 3 4 5 6 7 -- 查询所有文章信息 SELECT `default_article`.`id`, `default_article`.`title`, `default_article`.`desc`, `default_article`.`category_id`, `default_article`.`author_id` FROM `default_article`
变为了
1 2 3 4 5 6 7 8 9 10 SELECT `default_article`.`id`, `default_article`.`title`, `default_article`.`desc`, `default_article`.`category_id`, `default_article`.`author_id`, `default_category`.`id`, `default_category`.`title` FROM `default_article` INNER JOIN `default_category` ON (`default_article`.`category_id` = `default_category`.`id`)
好神奇,这不跟上面我们手动解决方案一样嘛,直接用了内连接查询。
既然select_related可以解决一对一或一对多的问题,可以解决多对多吗?我们直接来尝试下:
1 2 3 4 def list (request, *args, **kwargs ): """文章列表""" articles = Article.objects.select_related("category" , "tags" ).all () return render(request, 'list.html' , {"articles" :articles})
刷新前端
直接报了500:服务器错误:Invalid field name(s) given in select_related: 'tags'. Choices are: category, author
看来select_related仅能解决一对一和一对多的N+1问题
修改视图
1 2 3 4 def list (request, *args, **kwargs ): """文章列表""" articles = Article.objects.select_related("category" ).prefetch_related("tags" ).all () return render(request, 'list.html' , {"articles" :articles})
刷新前端
忽略前两条我们看看生成的sql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 -- 查询所有文章及对应的分类信息 SELECT `default_article`.`id`, `default_article`.`title`, `default_article`.`desc`, `default_article`.`category_id`, `default_article`.`author_id`, `default_category`.`id`, `default_category`.`title` FROM `default_article` INNER JOIN `default_category` ON (`default_article`.`category_id` = `default_category`.`id`) -- 查询上条语句查询的文章对应的标签 SELECT (`default_article_tags`.`article_id`) AS `_prefetch_related_val_article_id`, `default_tag`.`id`, `default_tag`.`title` FROM `default_tag` INNER JOIN `default_article_tags` ON (`default_tag`.`id` = `default_article_tags`.`tag_id`) WHERE `default_article_tags`.`article_id` IN (1, 2, 3)
我们从上面的7条sql变成了2条,这个数据量因为是测试,看着相差不大,当你的文章有100篇,那这种情况下原始查询方式对应的sql将有100*2+1=201条,而我们用了select_related和prefetch_related之后,还会只是2条,这就是差距。
DJANGO-REST-FRAMEWORK看N+1问题其实上面我用模板的形式展示主要是为了使用django-debug-toolbar让大家更直观,而现实情况是大部分都是前后端分离模式进行开发了,而这样django-debug-toolbar就看不出来运行监控了,为了还能继续使用django-debug-toolbar进行监控,我们需要在settings做下简单配置
1 2 3 REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES' : ('其他渲染器' , 'rest_framework.renderers.BrowsableAPIRenderer' ) }
rest_framework.renderers.BrowsableAPIRenderer这样我们就可以继续使用浏览器操作api了,而且也可以继续使用django-debug-toolbar进行监控了
视图我们直接使用ModelViewSet
1 2 3 class ArticleView (ModelViewSet ): queryset = Article.objects.all () serializer_class = ArticleSerializer
出不出现N+1的问题主要看我们序列话时有没有取关联表字段,我们这里故意取关联分类名让这个N+1复现
1 2 3 4 5 6 class ArticleSerializer (serializers.ModelSerializer): """Article序列化类""" category_title = serializers.ReadOnlyField(source="category.title" ) class Meta : model = Article fields = ["id" , "title" , "desc" , "category_title" ]
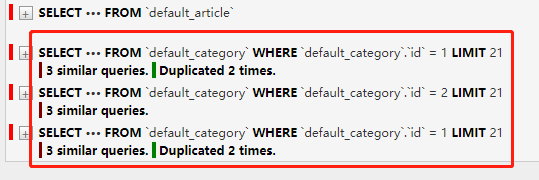
执行下来看3条数据,明显的执行了4条sql。
修改视图 添加关联查询select_related
1 2 3 class ArticleView (ModelViewSet ): queryset = Article.objects.select_related('category' ).all () serializer_class = ArticleSerializer
执行结果 1 2 3 4 5 6 7 8 9 10 ELECT `default_article`.`id `, `default_article`.`title`, `default_article`.`desc`, `default_article`.`category_id`, `default_article`.`author_id`, `default_category`.`id `, `default_category`.`title` FROM `default_article` INNER JOIN `default_category` ON (`default_article`.`category_id` = `default_category`.`id `)
4条sql变为了1条sql,效率大大提升了。
原始view我们还是直接queryset = Article.objects.all(),修改下序列化获取关联标签
1 2 3 4 5 6 7 class ArticleSerializer (serializers.ModelSerializer): """Article序列化类""" tags = serializers.StringRelatedField(many=True ) class Meta : model = Article fields = ["id" , "title" , "desc" , "tags" ]
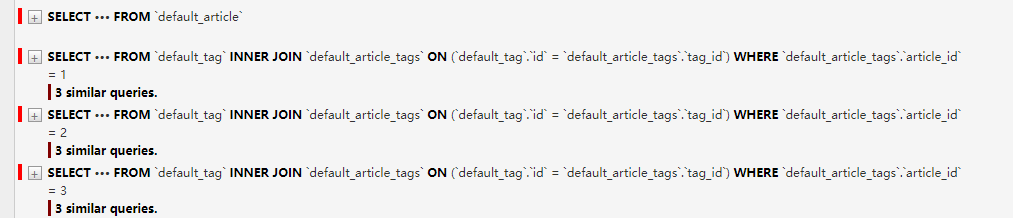
执行结果依然N+1
修改视图 1 queryset = Article.objects.prefetch_related("tags" ).all ()
执行结果 多对多产生的N+1问题,使用prefetch_related执行结果变为2条
联合使用 关联分类表、作者城市表(这样写直接附带关联了作者表)、标签表
1 queryset = Article.objects.select_related("category" , "author__city" ).prefetch_related("tags" ).all ()
序列化如下
1 2 3 4 category_title = serializers.ReadOnlyField(source="category.title" ) tags = serializers.StringRelatedField(many=True ) author = serializers.StringRelatedField() author_city = serializers.ReadOnlyField(source="author.city.title" )
对象数量为n,每个对象中有k个外键字段的话,就会导致n*k+1次SQL查询,我们在用这个公式计算出3条文章产生的sql为:3*4+1=13,实测也确实为13条
变为了2条,第二条还是多对多所必须产生的
如果我们获取tags对象时只希望获取以字母P开头的tag对象怎么办呢?我们可以使用Prefetch方法给prefect_related方法添加条件和属性。
1 2 3 4 5 6 7 8 9 10 Article.objects.all ().prefetch_related( Prefetch('tags' , queryset=Tag.objects.filter (name__startswith="P" )) ) Article.objects.all ().prefetch_related( Prefetch('tags' , queryset=Tag.objects.filter (name__startswith="P" )), to_attr='article_p_tag' )
为什么会有重复查询? 当我们使用Article.objects.all()查询文章时,我们做了第一次数据库查询,查询的是default_article数据表, 得到的数据只是文章对象列表,然而并没有包含与每篇文章相关联的category和tags对象信息。当我们调用了 article.category.name 和 tag.name显示category和tags的名字时,Django还需要重新查询default_category和default_tag数据表获取名字。for循环每运行一次,django都要对数据库进行一次查询,造成了极大的资源浪费。为什么我们不能再第一次获取文章列表的同时就获取每篇文章相关联的category和tags对象信息呢?Django考虑到了这一点,所以提供select_related和prefetch_related方法来提升数据库查询效率,其实用的就是SQL的JOIN方法。
select_related将会根据外键关系(注意: 仅限单对单和单对多关系 ),在执行查询语句的时候通过创建一条包含SQL inner join操作的SELECT语句来一次性获得主对象及相关对象的信息 。现在我们对list视图函数稍微进行修改,加入select_related方法,在查询文章列表时同时一次性获取相关联的category对象信息,这样调用 article.category.name时就不用再查询数据库了。
对于多对多字段 ,你不能使用select_related方法,这样做是为了避免对多对多字段执行JOIN操作从而造成最后的表非常大。Django提供了prefect_related方法来解决这个问题。prefect_related可用于多对多关系字段,也可用于反向外键关系(related_name)。我们对之前的list视图函数再做进一步修改,在查询文章列表的同时返回相关tags信息。
总结 当你查询单个主对象或主对象列表并需要在模板或其它地方中使用到每个对象的关联对象信息时,请一定记住使用select_related和prefetch_related一次性获取所有对象信息,从而提升数据库查询效率,避免重复查询。如果不确定是否有重复查询,可使用django-debug-toolbar查看。
对与单对单或单对多外键ForeignKey字段,使用select_related方法 对于多对多字段和反向外键关系,使用prefetch_related方法 两种方法均支持双下划线指定需要查询的关联对象的字段名 使用Prefetch方法可以给prefetch_related方法额外添加额外条件和属性。 Django >= 1.7,链式调用的select_related相当于使用可变长参数。Django < 1.7,链式调用会导致前边的select_related失效,只保留最后一个。