pandas核心知识操作笔记
Pandas 应用 Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例
以为大牛公开的python学习库,爱学习的小伙伴可以去学习下https://github.com/SeafyLiang/Python_study
引入依赖
1 | # 导入模块 |
1 | 下载中文字体 |
算法相关依赖
1 | # 数据归一化 |
获取数据
1 | from sqlalchemy import create_engine |
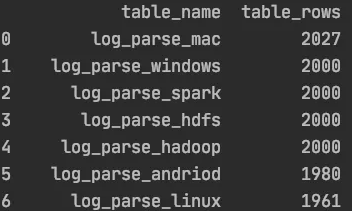
生成df
1 | # list转df |
重命名列
1 | # 重命名列 |
增加列
1 | # df2df |
缺失值处理
1 | # 检查数据中是否含有任何缺失值 |
独热编码
1 | df_encoded = pd.get_dummies(df_data) |
替换值
1 | # 按列值替换 |
删除列
1 | df_jj2.drop(['coll_time', 'polar', 'conn_type', 'phase', 'id', 'Unnamed: 0'],axis=1,inplace=True) |
数据筛选
1 | # 取第33行数据 |
差值计算
1 | # axis=0或index表示上下移动, periods表示移动的次数,为正时向下移,为负时向上移动。 |
数据修改
1 | # 删除最后一行 |
时间格式转换
1 | # 时间戳转时间字符串 |
设置索引列
1 | df_jj2yyb_small_noise = df_jj2yyb_small_noise.set_index('timestamp') |
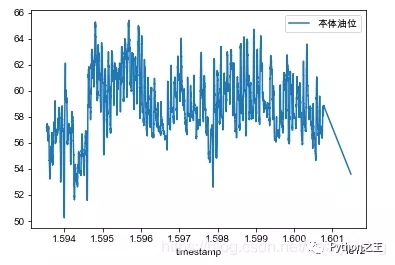
折线图
1 | fig, ax = plt.subplots() |
1 | plt.figure(figsize=(20, 6)) |
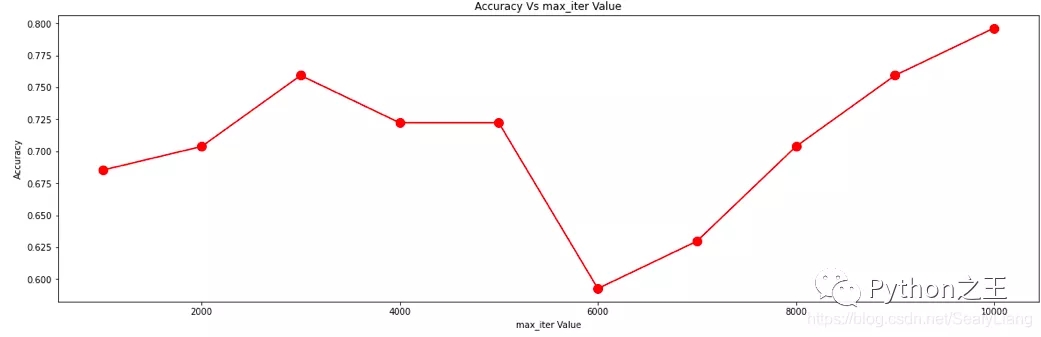
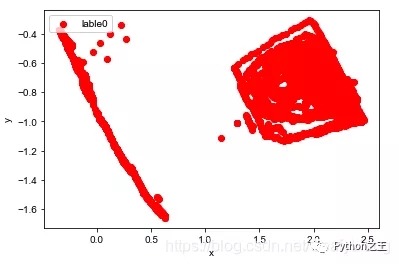
散点图
1 | plt.scatter(df[:, 0], df[:, 1], c="red", marker='o', label='lable0') |
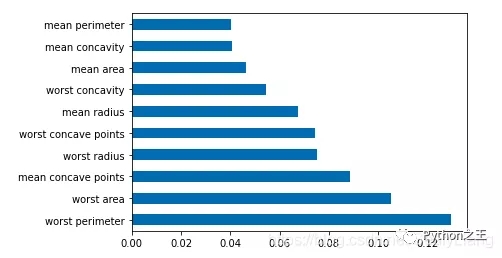
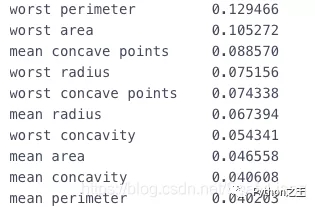
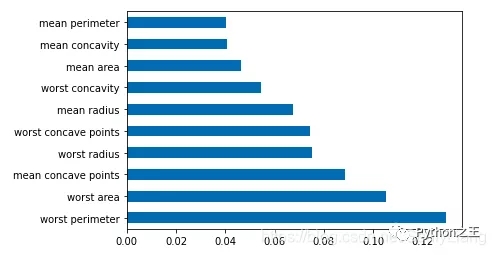
柱状图
1 | df = pd.Series(tree.feature_importances_, index=data.columns) |
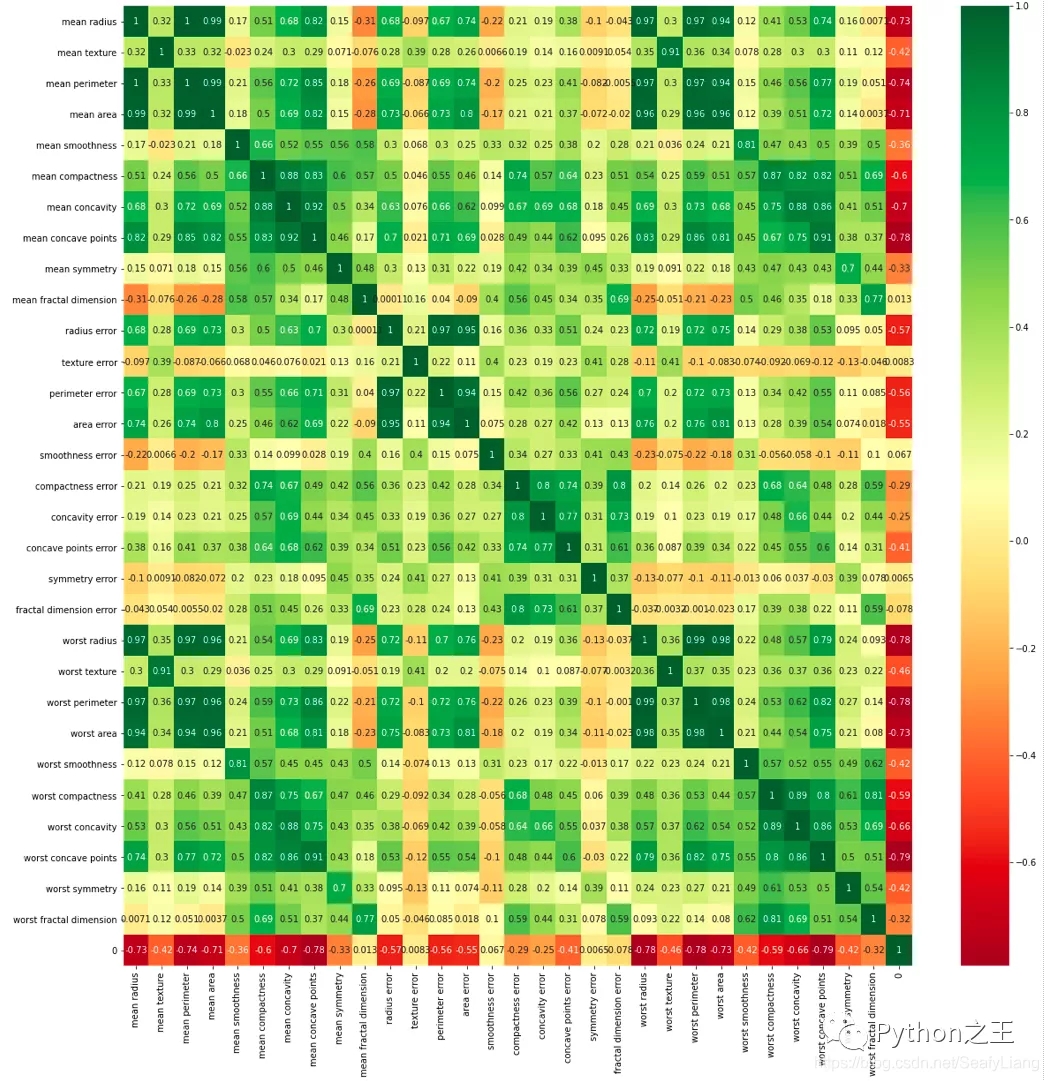
热力图
1 | df_corr = combine.corr() |
66个最常用的pandas数据分析函数
1 | df #任何pandas DataFrame对象 |
从各种不同的来源和格式导入数据
1 | pd.read_csv(filename) # 从CSV文件 |
导出数据
1 | df.to_csv(filename) # 写入CSV文件 |
创建测试对象
1 | pd.DataFrame(np.random.rand(20,5)) # 5列20行随机浮点数 pd.Series(my_list) # 从一个可迭代的序列创建一个序列 my_list |
查看、检查数据
1 | df.head(n) # DataFrame的前n行 |
数据选取
1 | 使用这些命令选择数据的特定子集。 |
数据清理
1 | df.columns = ['a','b','c'] # 重命名列 |
筛选,排序和分组依据
1 | df[df[col] > 0.5] # 列 col 大于 0.5 df[(df[col] > 0.5) & (df[col] < 0.7)] # 小于 0.7 大于0.5的行 |
数据合并
1 | df1.append(df2) # 将df2添加 df1的末尾 (各列应相同) |
数据统计
1 | df.describe() # 数值列的摘要统计信息 |
16个函数,用于数据清洗
1 | # 导入数据集 |
1.cat函数
用于字符串的拼接
1 | df["姓名"].str.cat(df["家庭住址"],sep='-'*3) |
2.contains
判断某个字符串是否包含给定字符
1 | df["家庭住址"].str.contains("广") |
3.startswith/endswith
判断某个字符串是否以…开头/结尾
1 | # 第一个行的“ 黄伟”是以空格开头的 |
4.count
计算给定字符在字符串中出现的次数
1 | df["电话号码"].str.count("3") |
5.get
获取指定位置的字符串
1 | df["姓名"].str.get(-1) |
6.len
计算字符串长度
1 | df["性别"].str.len() |
7.upper/lower
英文大小写转换
1 | df["英文名"].str.upper() |
8.pad+side参数/center
在字符串的左边、右边或左右两边添加给定字符
1 | df["家庭住址"].str.pad(10,fillchar="*") # 相当于ljust() |
9.repeat
重复字符串几次
1 | df["性别"].str.repeat(3) |
10.slice_replace
使用给定的字符串,替换指定的位置的字符
1 | df["电话号码"].str.slice_replace(4,8,"*"*4) |
11.replace
将指定位置的字符,替换为给定的字符串
1 | df["身高"].str.replace(":","-") |
12.replace
将指定位置的字符,替换为给定的字符串(接受正则表达式)
- replace中传入正则表达式,才叫好用;- 先不要管下面这个案例有没有用,你只需要知道,使用正则做数据清洗多好用;
1 | df["收入"].str.replace("\d+\.\d+","正则") |
13.split方法+expand参数
搭配join方法功能很强大
1 | # 普通用法 |
14.strip/rstrip/lstrip
去除空白符、换行符
1 | df["姓名"].str.len() |
15.findall
利用正则表达式,去字符串中匹配,返回查找结果的列表
- findall使用正则表达式,做数据清洗,真的很香!
1 | df["身高"] |
16.extract/extractall
接受正则表达式,抽取匹配的字符串(一定要加上括号)
1 | df["身高"].str.extract("([a-zA-Z]+)") |