Django之导入导出神器django-import-export
django-import-export 是一个 Django 应用程序和库,用于导入和导出数据,包括管理集成。
官方给出的特征如下:
- 支持多种格式(Excel、CSV、JSON……以及tablib支持的所有其他格式)
- 用于导入的管理员集成
- 预览导入更改
- 用于导出的管理员集成
- 导出有关管理员过滤器的数据
这篇文章不会讲的特别全面,只会记录常用部分,另外这个库跟我之前封装的一个基于openpyxl封装的一个mixin有功能重叠的部分,感觉之前的接入到项目也很好用,后续会考虑二者做下对比和取舍。
安装与配置
django-import-export 在 Python 包索引 (PyPI) 上可用,因此可以使用标准 Python 工具安装它,例如pip或easy_install:
1 | $ pip install django-import-export |
这将自动安装 tablib 支持的许多格式。如果您需要其他格式,例如clior ,您应该安装适当的 tablib 依赖项(例如)。在tablib 格式文档页面上阅读更多内容。Pandas DataFrame``pip install tablib[pandas]
或者,您可以直接安装 git 存储库以获取开发版本:
1 | $ pip install -e git+https://github.com/django-import-export/django-import-export.git#egg=django-import-export |
现在,您可以开始了,除非您也想从管理员中使用 django-import-export。在这种情况下,您需要将其添加到您的INSTALLED_APPS并让 Django 收集其静态文件。
1 | # settings.py |
还有一个可选的配置,我通常这样添加:
1 | IMPORT_EXPORT_USE_TRANSACTIONS = True |
默认值为False。它确定库是否会在数据导入中使用数据库事务,以确保安全。
Resources
django-import-export库使用Resource的概念,它的类定义非常类似于Django处理模型表单和管理类的方式。
在文档中,作者建议将与资源相关的代码放在admin.py文件。但是,如果实现与Django admin没有关系,我通常更喜欢在app文件夹里创建一个名为resources.py。
models.py
1 | from django.db import models |
resources.py
1 | from import_export import resources |
这是最简单的定义,代码来看跟我们的models或者serializer很像,毕竟django就是这样做事情的。
简单介绍一下resources中meta的几个参数,其实从字面大概都能猜出来。
export_order
调整字段顺序
要导入的数据(Excel、csv这些),可能字段顺序和Model定义的字段顺序不一样,这时就得在Resource里手动调整一下
其中export_order是导出的字段顺序,fields是指定哪些字段需要导入,导入的时候是根据数据文件的列名来导入的,所以Excel、csv或者json文件里面字段名就要和fields里的或者是Model里的字段名一样,才可以进行导入。
exclude
排除字段
顾名思义,就拿那个Person的模型来说,Model定义里没有指定主键,那Django会安排一个默认的主键字段id,但是我们导入数据的Excel里应该是没有这个id的,这样就没法导入,于是我们得把这个id字段排除了,很简单,在Meta里这行代码
1 | exclude = ['id'] |
import_id_fields
设置主键字段
也是顾名思义,假如我们数据库本来就有很多人了,现在需要通过导入一个Excel来更新这群人的数据,那我就得把找一个字段来设置成主键字段,不然导入就变成新增了,跟前面提到的一样,一般Excel里不会有数据库主键id的,所以这里我选择了人名(假设我们这人名都不重复的)
1 | import_id_fields = ['name'] |
自定义列名
按照前文配置导出来的Excel,列名全是字段名,也就是英文的,但我想中文列名啊,也可以,就是需要花一点代码,为了更方面码字,我这里直接用我项目里的代码了,模型和resources如下:
1 | class Case(models.Model): |
这样就实现了,so easy。其中Field里的attribute是指这个字段对应Model里的属性也就是字段名,column_name顾名思义就是列名。
然后可能有同学要问,Model里已经给每个字段都设置了verbose_name了,这里还要在column_name里再写一遍是不是重复了?
别急,也很简单,既然有verbose_name,那直接拿来用就完事啦~
1 | name = Field(attribute='name', column_name=Case.name.field.verbose_name) |
这就完事美滋滋啦~
加入自定义的列
最后一个,如果想在导出的数据中加入Model里不存在的字段,行不?
比如可以,类似我们drf中serializer中的get_字段()方法,这里前缀换成了dehydrate
1 | preoperative_media = Field(column_name='术前诊断附件') |
可以看到就是先在export_order里添加这个字段,然后再加这行new_field = Field(column_name='一个新的字段'),然后下面加一个类方法来实现生成这个字段的值,这个方法是以dehydrate_字段名这样的格式来命名的,具体可以根据实际来写。
choices语义项
像性别、状态啥的我们基本都会使用choice的枚举值,导出来发现都是数字或者字母标识,对用户不太友好,那就同样参考drf吧,
1 | status = Field(column_name="审核状态", attribute='get_status_display') |
直接get_字段名_display即可
像关联字段的我上面示例里也是跟其他字段一样,django-import-export帮我们直接转为关联model的__str__()方法的值了。
工作簿名称
无意中发现导出来的excel工作簿名称为“Tablib Dataset”
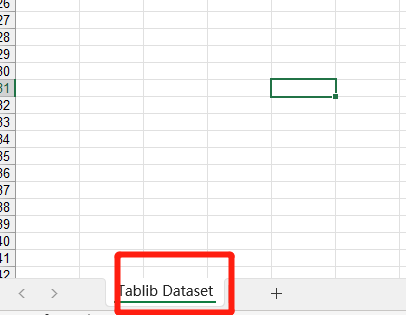
虽然也没什么问题,但是对于系统交付给客户来使用的话就不够友好了,客户甚至还想自定义这个工作簿的名称,那我们应该怎么改呢?
我是翻遍了整个django-import-export文档也没找到修改sheet的方法,但是可以知道的是django-import-export依赖的都是tablib,如果这个默认title不是django–import-export配置的,那一定是tablib了,果然我们到导入方法里看到了使用tablib的Dataset,这里要做的就是初始化表数据了。
1 | data = tablib.Dataset(headers=headers) |
我们在Dataset类里看到了这样的类注释,title给这个表数据设置一个标题
1 | :param \*args: (optional) list of rows to populate Dataset |
那我们试试吧
1 | data = tablib.Dataset(headers=headers, title="Sheet") |
再次尝试导出
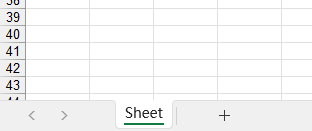
可以看到已经成功了,所以如果以后导出需要自定义sheet标题,可以尝试重写django-import-export中的export方式,通过传参来修改对应sheet标题。
导出数据
筛选啥的真的跟这个无关了,我们直接导出的是过滤过的数据
1 | # 过滤好的数据 |
响应给浏览器
1 | # csv格式 |
文章有点水哈,只是记录了自己暂时用到的部分,后面用到其他功能在更新上去吧