今日在做一个与爬虫相关的项目,奈何自己是爬虫菜鸟,于是走捷径想用selenium去爬取目标去网站,奈何目标很强大,某音短视频,网页反爬策略也是很多,后面我这里会一一列出。
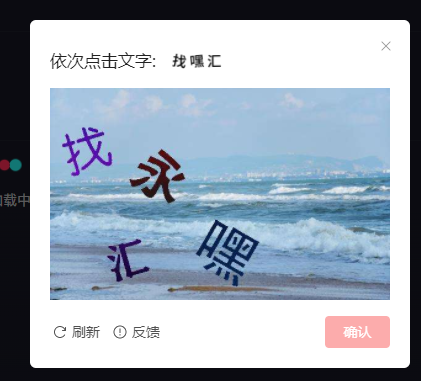
验证码如图所示:
其实这个验证码日常还是很常见的,但是实际操作发现,想找一个同样的验证码去测试破解还是很困难的。如果你想着直接在某音短视频直接破解你会发现怎么都触发不了这个验证码的出现,反倒是挂到服务器爬取的时候,经常会卡死到验证码这里。
后来实测发现触发该验证码并不是时间久才能触发的,当弹出滑动验证码时下拉滚动条,原来的滑动验证码就会变成上图中的中文验证码,如此便方便我们测试破解它了。关于滑动验证码的破解要参考我另外一篇文章**selenium篇之滑动验证码 **了。
破解前的准备 人工智能机器学习相关知识库
第三方验证识别平台(我这里使用的是快识别)
第一种方法**selenium篇之滑动验证码 **中提到过,相对来说有一定的学习成本,方式二真的适合快速开发,价格也不贵,所以本文直接采用第二种方式。
代码正文 为了方便,我这里代码稍微有点乱,大家自己项目里整合下即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import jsonimport randomimport timeimport requestsfrom selenium import webdriverfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.common.by import Bydef base64_api (uname, pwd, img_base64, typeid ): """ 获取验证码缺口 :param uname: 646547989 :param pwd: 646547989 :param img_base64: selenium可直接拿到验证码base64 :param typeid: 27 :return:|分割的坐标组 """ data = {"username" : uname, "password" : pwd, "typeid" : typeid, "image" : img_base64} url = "http://api.ttshitu.com/predict" result = json.loads(requests.post(url, json=data).text) if result['success' ]: return result["data" ]["result" ] else : return result["message" ] return "" def is_show_coordinate (): """判断是否中文坐标验证码""" if "依次点击文字" in driver.page_source: verify_dom = driver.find_element(By.XPATH, '//*[@id="captcha_container"]/div' ) verify_base64 = verify_dom.screenshot_as_base64 result = base64_api(uname='您的用户名' , pwd='您的密码' , img_base64=verify_base64, typeid=27 ) positions = result.split("|" ) print ("文字坐标:" , positions) for p in positions: x, y = p.split(',' ) ActionChains(driver).move_to_element_with_offset(verify_dom, x, y).click().perform() time.sleep(random.random() * 2 ) verify_dom.find_element(By.XPATH, 'div[3]/div[2]' ).click() if __name__ == '__main__' : option = webdriver.ChromeOptions() option.add_experimental_option('excludeSwitches' , ['enable-automation' ]) service = Service(r"chromedriver.exe" ) driver = webdriver.Chrome(service=service, options=option) driver.maximize_window() driver.get('https://www.douyin.com/video/7037691282721934599' ) time.sleep(random.random() * 5 ) driver.execute_script('window.scrollTo(0, document.body.scrollHeight)' ) time.sleep(10 ) is_show_coordinate() time.sleep(1000 )