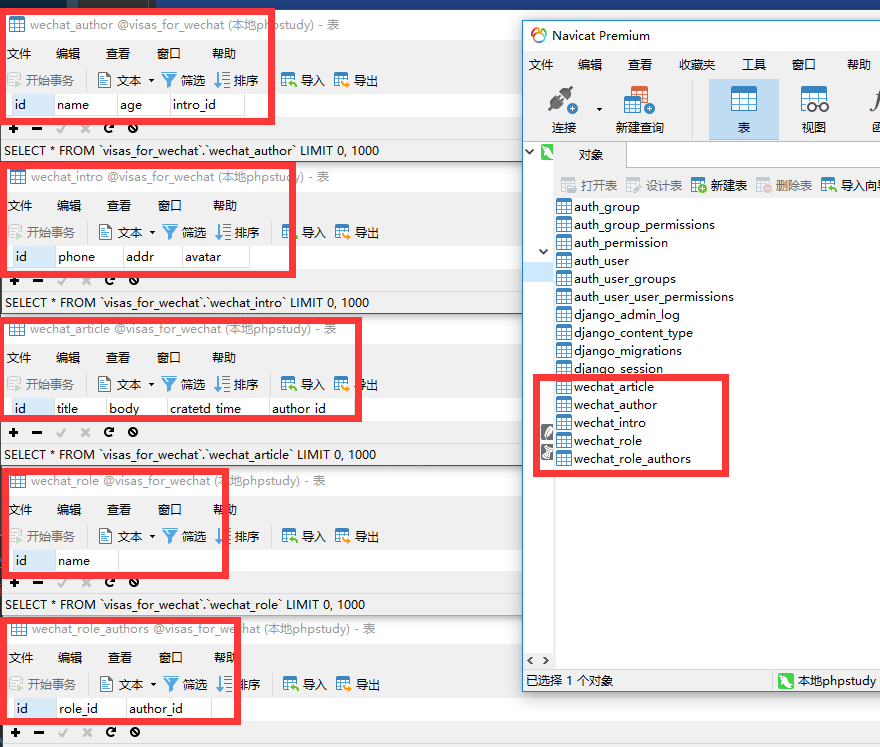
Arcticle模型author字段中我们设置了参数related_name,这个参数主要就是用来做反向查询的,我们这里设置了反向查询名称为articles,此时在使用上方的article_set,就会报错:`’Author’ object has no attribute ‘article_set’
from django.db.models import Avg from django.db.models import Max from django.db.models import Min # 查询所有文章的平均查看数,最大查看数,最小查看数 query_result = Article.objects.all().aggregate(avg_views = Avg('views'), max_views=Max('views'), min_views=Min('views')) print(query_result) # 输出:{'avg_views': 2156.0, 'max_views': 9595, 'min_views': 34}
分组查询
单表查询每一个班级对应的学生数
1 2 3 4 5
from django.db.models import Count query_result = Student.objects.values('classes').annotate(nums = Count('id')) print(query_result) # 输出:<QuerySet [{'classes': '软件二班', 'nums': 4}, {'classes': '图像一班', 'nums': 4}, {'classes': '师范一班', 'nums': 3}]> # sql:SELECT `wechat_student`.`classes`, COUNT(`wechat_student`.`id`) AS `nums` FROM `wechat_student` GROUP BY `wechat_student`.`classes` ORDER BY NULL LIMIT 21;
多表联合分组查询每个作者及其对应发布的文章数
1 2 3 4 5
from django.db.models import Count query_result = Author.objects.values('id').annotate(sums = Count('articles')).values('name', 'sums') print(query_result) # 输出:<QuerySet [{'name': '孙悟空', 'sums': 6}, {'name': '猪八戒', 'sums': 5}, {'name': '沙悟净', 'sums': 2}, {'name': '小白龙', 'sums': 2}, {'name': '刘德华', 'sums': 0}, {'name': '周杰伦', 'sums': 0}]> # sql:SELECT `wechat_author`.`name`, COUNT(`wechat_article`.`id`) AS `sums` FROM `wechat_author` LEFT OUTER JOIN `wechat_article` ON (`wechat_author`.`id` = `wechat_article`.`author_id`) GROUP BY `wechat_author`.`id` ORDER BY NULL LIMIT 21;
分组聚合查询示例
查询每个作者发表的文章最少查看数
1 2 3 4 5 6 7 8 9 10 11 12
from django.db.models import Min query_result = Author.objects.annotate(min_views=Min('articles__views')) for author_obj in query_result: print(author_obj.name, author_obj.min_views) # 输出: # 孙悟空 56 # 猪八戒 154 # 沙悟净 34 # 小白龙 158 # 刘德华 None # 周杰伦 None # sql:SELECT `wechat_author`.`id`, `wechat_author`.`name`, `wechat_author`.`age`, `wechat_author`.`intro_id`, MIN(`wechat_article`.`views`) AS `min_views` FROM `wechat_author` LEFT OUTER JOIN `wechat_article` ON (`wechat_author`.`id` = `wechat_article`.`author_id`) GROUP BY `wechat_author`.`id` ORDER BY NULL;
或者使用values
1 2 3 4 5
from django.db.models import Min query_result = Author.objects.annotate(min_views=Min('articles__views')).values('name', 'min_views') print(query_result) # 输出:<QuerySet [{'name': '孙悟空', 'min_views': 56}, {'name': '猪八戒', 'min_views': 154}, {'name': '沙悟净', 'min_views': 34}, {'name': '小白龙', 'min_views': 158}, {'name': '刘德华', 'min_views': None}, {'name': '周杰伦', 'min_views': None}]> # sql:SELECT `wechat_author`.`name`, MIN(`wechat_article`.`views`) AS `min_views` FROM `wechat_author` LEFT OUTER JOIN `wechat_article` ON (`wechat_author`.`id` = `wechat_article`.`author_id`) GROUP BY `wechat_author`.`id` ORDER BY NULL LIMIT 21;
查询每个角色的作者数量
1 2 3 4 5
from django.db.models import Count query_result = Role.objects.annotate(authors_sums = Count('authors')).values('name', 'authors_sums') print(query_result) #输出:<QuerySet [{'name': '神仙', 'authors_sums': 4}, {'name': '将军', 'authors_sums': 2}, {'name': '大王', 'authors_sums': 1}, {'name': '龙族', 'authors_sums': 1}, {'name': '歌手', 'authors_sums': 2}]> #sql:SELECT `wechat_role`.`name`, COUNT(`wechat_role_authors`.`author_id`) AS `authors_sums` FROM `wechat_role` LEFT OUTER JOIN `wechat_role_authors` ON (`wechat_role`.`id` = `wechat_role_authors`.`role_id`) GROUP BY `wechat_role`.`id` ORDER BY NULL LIMIT 21;
统计所有以沙开头的作者对应的角色数
1 2 3 4 5
from django.db.models import Count query_result = Author.objects.filter(name__startswith='沙').annotate(role_sums = Count('roles')).values('name', 'role_sums') print(query_result) # 输出:<QuerySet [{'name': '沙悟净', 'role_sums': 2}, {'name': '沙溢', 'role_sums': 1}]> # sql:SELECT `wechat_author`.`name`, COUNT(`wechat_role_authors`.`role_id`) AS `role_sums` FROM `wechat_author` LEFT OUTER JOIN `wechat_role_authors` ON (`wechat_author`.`id` = `wechat_role_authors`.`author_id`) WHERE `wechat_author`.`name` LIKE BINARY '沙%' GROUP BY `wechat_author`.`id` ORDER BY NULL LIMIT 21;
查询不止一个角色身份的作者
1 2 3 4 5
from django.db.models import Count query_result = Author.objects.annotate(role_sums=Count('roles')).filter(role_sums__gt = 1) print(query_result) # 输出:<QuerySet [<Author: 孙悟空>, <Author: 猪八戒>, <Author: 沙悟净>, <Author: 小白龙>, <Author: 刘德华>, <Author: 周杰伦>]> # sql:SELECT `wechat_author`.`id`, `wechat_author`.`name`, `wechat_author`.`age`, `wechat_author`.`intro_id`, COUNT(`wechat_role_authors`.`role_id`) AS `role_sums` FROM `wechat_author` LEFT OUTER JOIN `wechat_role_authors` ON (`wechat_author`.`id` = `wechat_role_authors`.`author_id`) GROUP BY `wechat_author`.`id` HAVING COUNT(`wechat_role_authors`.`role_id`) > 1 ORDER BY NULL LIMIT 21;
查询每一个作者,按其对应的角色数量排序
1 2 3 4 5
from django.db.models import Count query_result = Author.objects.annotate(role_sums = Count('roles')).order_by('role_sums').values('name', 'role_sums') print(query_result) # 输出:<QuerySet [{'name': '沙溢', 'role_sums': 1}, {'name': '刘德华', 'role_sums': 2}, {'name': '周杰伦', 'role_sums': 2}, {'name': '小白龙', 'role_sums': 3}, {'name': '沙悟净', 'role_sums': 3}, {'name': '猪八戒', 'role_sums': 3}, {'name': '孙悟空', 'role_sums': 3}]> # sql:SELECT `wechat_author`.`name`, COUNT(`wechat_role_authors`.`role_id`) AS `role_sums` FROM `wechat_author` LEFT OUTER JOIN `wechat_role_authors` ON (`wechat_author`.`id` = `wechat_role_authors`.`author_id`) GROUP BY `wechat_author`.`id` ORDER BY `role_sums` ASC LIMIT 21;