DataFrame基础入门笔记
在Python的Pandas库中,DataFrame是一个二维的标签化数据结构,可以看作是表格型数据结构,其中每个列可以是不同的数据类型(数字、字符串、布尔值等),并且每列都有一个标签或名称。
与Series相比,DataFrame提供了更多的功能和灵活性,可以用来处理和分析更复杂的数据集。例如,可以使用列名来访问或修改数据,进行各种数据清洗和转换操作,或者进行基于多个列的数值计算。
DataFrame是一个表格型的数据结构,含有一组有序的列。DataFrame可以被看做是由Series组成的字典并且共用一个索引。
创建方式
创建方式有很多种,如下:
1 | # 使用字典创建 |
其实说白了,只要是符合DataFrame的二维数组(列表)形式,都可以作为DataFrame的数据源
1 | # 三维数组 |
但是实际开发中,我们的数据源很少使用上述形式读取进来,更多的是通过文件、sql等
这里简单通过一个csv文件做个示例,事实上pd读取文件不止csv,还有excel/json/xml等等
1 | # 查看data.csv文件内容 |
写示例
1 | In [21]: df1 |
常用属性
index
获取索引
1 | In [33]: df =pd.DataFrame(np.random.randint(1, 20, 6).reshape((3, 2)), index=['x', 'y', 'z'], columns=['a', 'b']) |
T
转置
1 | In [36]: df |
columns
获取列索引
1 | In [39]: df |
values
获取值数组
1 | In [42]: df |
describe()
获取快速统计
1 | In [45]: df |
索引和切片
DataFrame是一个二维数据类型,所以有行索引和列索引。
DataFrame同样可以通过标签和位置两种方法进行索引和切片
loc属性和iloc属性.
使用方法: 逗号隔开,前面是行索引,后面是列索引
行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配
1 | In [57]: df |
数据对齐和缺失数据
DataFrame对象在运算时,同样会进行数据对齐,其行索引和列索引分别对齐
1 | In [109]: df1 = pd.DataFrame({'one':[2, 3, 5, 6], 'two':[2, 5, 9, 3]}, index=['a', 'b', 'c', 'd']) |
DataFrame处理缺失数据的相关方法dropna(axis=0,where='any'....
1 | In [119]: df |
假如我们只删除一行中所有列都是NaN的行呢
1 | In [124]: df.loc['e'] = [np.nan, np.nan] |
fillna()
1 | In [115]: df |
isnull()
1 | In [128]: df |
notnull()
1 | In [132]: df |
常用方法
默认nan不参与计算
mean(axis=0,skipna=False)
对列 (行) 求平均值
1 | In [142]: df |
sum(axis=1)
对列 (行) 求和
1 | In [150]: df |
sort_index(axis, ..., ascending)
对列 (行) 索引排序
1 | In [155]: df |
sort_values(by, axis, ascending)
按某一列 (行) 的值排序
1 | In [160]: df |
apply(func,axis=0)
将自定义函数应用在各行或者各列上func可返回标量或者Series
1 | In [169]: df |
NumPy的通用函数同样适用于pandas
时间对象
时间序列类型
- 时间戳: 特定时刻
- 固定时期: 如2017年7月
- 时间间隔: 起始时间-结束时间
Python标准库处理时间对象: datetime
datetime日常大家都在用,这里不再细说了
灵活处理时间对象: dateutil
dateutil.parser.parse()
dateutil模块是由Gustavo Niemeyer在2003年编写而成的对日期时间操作的第三方模块
dateutil模块对Python内置的datetime模块进行扩展时区和解析
dateutil库主要有两个模块:parser和rrule,其中parser可以将字符串解析成datetime,而rrule则是根据定义的规则来生成datetime
dateutil模块特点:
- 能够计算日期时间相对增量,例如下周、下个月、明年、每月的最后一周等
- 可以计算两个给定日期和/或日期时间对象之间的相对增量
- 支持多种时区格式文件的解析,例如UTC时区、TZ时区等
- 支持包括RFC字符串或其他任何字符串格式的通用日期时间解析
安装
1 | pip install python-dateutil |
Dateutil库常用模块
dateutil库常用模块有三个:parser、rrule和relativedelta
1 | from dateutil import parser, rrule, relativedelta |
parser
parser用于将字符串解析成datetime,字符串可以很随意,可以用日期时间的英文单词,可以用横线、逗号、空格等做分隔符
1 | ''' |
parser使用示例如下:
1 | # 没指定时间默认0点,没指定日期默认当天,没指定年份默认当年 |
rrule
rrule用于将字符串解析成datetime
1 | ''' |
rrule使用示例如下:
1 | # 生成一个连续的日期列表 |
relativedelta
relativedelta主要用于日期时间偏移
1 | ''' |
relativedelta使用示例如下:
1 | # datetime.timedelta与relativedelta.relativedelta() |
成组处理时间对象: pandas
pd.to datetime()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 指定日期轉成datetime索引
In [197]: pd.to_datetime(['2024-01-05', '2023/12/12', '20230912'])
Out[197]: DatetimeIndex(['2024-01-05', '2023-12-12', '2023-09-12'], dtype='datetime64[ns]', freq=None)
# 生成年月日dataframe
In [194]: pd.DataFrame({'year': [2015, 2016],
...: 'month': [2, 3],
...: 'day': [4, 5]})
Out[194]:
year month day
0 2015 2 4
1 2016 3 5
In [195]: pd.to_datetime(df)
Out[195]: DatetimeIndex(['2024-01-05', '2023-12-12'], dtype='datetime64[ns]', freq=None)date_range返回一个固定频率的
datatime索引语法:
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, inclusive='both', *, unit=None, **kwargs)[source]主要参数:
start
类似
datetime的字符串,可选,生成日期的左边界。end
类似
datetime的字符串,可选,生成日期的右边界。periods
生成的周期数,如:2001-01-01至2001-01-31,periods=15,表示将这个时间段的日期分成15个,2001-01-01,2001-01-03,2001-01-05……2001-01-31
freq
时间频率默认为
D,可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es),S(econd),A(year),…
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75# 按天获取2023-12-25至2023-01-09之间的日期
In [2]: pd.date_range('2023-12-25', '2024/01/09')
Out[2]:
DatetimeIndex(['2023-12-25', '2023-12-26', '2023-12-27', '2023-12-28',
'2023-12-29', '2023-12-30', '2023-12-31', '2024-01-01',
'2024-01-02', '2024-01-03', '2024-01-04', '2024-01-05',
'2024-01-06', '2024-01-07', '2024-01-08', '2024-01-09'],
dtype='datetime64[ns]', freq='D')
# 获取2001-04-01至2001-04-20之间,平均分成10个时间点
In [13]: pd.date_range('2001-04-01', '2001/04/20', periods=10)
Out[13]:
DatetimeIndex(['2001-04-01 00:00:00', '2001-04-03 02:40:00',
'2001-04-05 05:20:00', '2001-04-07 08:00:00',
'2001-04-09 10:40:00', '2001-04-11 13:20:00',
'2001-04-13 16:00:00', '2001-04-15 18:40:00',
'2001-04-17 21:20:00', '2001-04-20 00:00:00'],
dtype='datetime64[ns]', freq=None)
# 获取2023-12-25'至'2024/01/09每相隔1个小时的时间点
In [6]: pd.date_range('2023-12-25', '2024/01/09', freq='H')
Out[6]:
DatetimeIndex(['2023-12-25 00:00:00', '2023-12-25 01:00:00',
'2023-12-25 02:00:00', '2023-12-25 03:00:00',
'2023-12-25 04:00:00', '2023-12-25 05:00:00',
'2023-12-25 06:00:00', '2023-12-25 07:00:00',
'2023-12-25 08:00:00', '2023-12-25 09:00:00',
...
'2024-01-08 15:00:00', '2024-01-08 16:00:00',
'2024-01-08 17:00:00', '2024-01-08 18:00:00',
'2024-01-08 19:00:00', '2024-01-08 20:00:00',
'2024-01-08 21:00:00', '2024-01-08 22:00:00',
'2024-01-08 23:00:00', '2024-01-09 00:00:00'],
dtype='datetime64[ns]', length=361, freq='H')
# 获取2023-01-25至2024-01-09每月1号
In [8]: pd.date_range('2023-01-25', '2024/01/09', freq='MS')
Out[8]:
DatetimeIndex(['2023-02-01', '2023-03-01', '2023-04-01', '2023-05-01',
'2023-06-01', '2023-07-01', '2023-08-01', '2023-09-01',
'2023-10-01', '2023-11-01', '2023-12-01', '2024-01-01'],
dtype='datetime64[ns]', freq='MS')
# 获取2023-01-25至2024-01-09每月1号,每个12小时的时间点
In [9]: pd.date_range('2023-01-25', '2024/01/09', freq='12h')
Out[9]:
DatetimeIndex(['2023-01-25 00:00:00', '2023-01-25 12:00:00',
'2023-01-26 00:00:00', '2023-01-26 12:00:00',
'2023-01-27 00:00:00', '2023-01-27 12:00:00',
'2023-01-28 00:00:00', '2023-01-28 12:00:00',
'2023-01-29 00:00:00', '2023-01-29 12:00:00',
...
'2024-01-04 12:00:00', '2024-01-05 00:00:00',
'2024-01-05 12:00:00', '2024-01-06 00:00:00',
'2024-01-06 12:00:00', '2024-01-07 00:00:00',
'2024-01-07 12:00:00', '2024-01-08 00:00:00',
'2024-01-08 12:00:00', '2024-01-09 00:00:00'],
dtype='datetime64[ns]', length=699, freq='12H')
# 获取2023-01-25至2024-01-09每月1号,每间隔2小时20分的时间点
In [19]: pd.date_range('2023-01-25', '2024/01/09', freq='2h20min')
Out[19]:
DatetimeIndex(['2023-01-25 00:00:00', '2023-01-25 02:20:00',
'2023-01-25 04:40:00', '2023-01-25 07:00:00',
'2023-01-25 09:20:00', '2023-01-25 11:40:00',
'2023-01-25 14:00:00', '2023-01-25 16:20:00',
'2023-01-25 18:40:00', '2023-01-25 21:00:00',
...
'2024-01-08 01:20:00', '2024-01-08 03:40:00',
'2024-01-08 06:00:00', '2024-01-08 08:20:00',
'2024-01-08 10:40:00', '2024-01-08 13:00:00',
'2024-01-08 15:20:00', '2024-01-08 17:40:00',
'2024-01-08 20:00:00', '2024-01-08 22:20:00'],
dtype='datetime64[ns]', length=3590, freq='140T')
时间序列
时间序列就是以时间对象为索引的Series或DataFrame。
datetime对象作为索引时是存储在Datetimelndex对象中的。
时间序列特殊功能
- 传入“年”或“年月”作为切片方式
- 传入日期范围作为切片方式
- 丰富的函数支持: resample(), strftime(),……
1 | # 获取2021-01-01开始1000天的时间索引,值为1-100的随机数 |
文件处理
数据文件常用格式: csv (以某间隔符分割数据
pandas读取文件: 从文件名、URL、文件对象中加载数据
read_csv 默认分隔符为逗号
pandas支持从多种文件格式中读取数据,我们这里就以csv为例
文件读取
read_csv、函数主要参数:
sep 指定分隔符,可用正则表达式如s+
header=None 指定文件无列名names指定列索引名index_col指定某列作为索引usecols指定要读取的列skiprows指定跳过某些行na_values 指定某些字符串表示缺失值
parse_dates 指定某些列是否被解析为日期,类型为布尔值或列表
为True是会将日期索引列解析为日期;列表时,指定列解析为日期
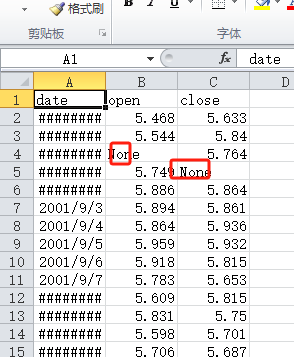
1 | # 默认读取一支股票的数据 |
文件写入
写入到csv文件: to_csv函数
写入文件函数的主要参数
- sep 指定文件分隔符
na_rep指定缺失值转换的字符串,默认为空字符串- header=False 不输出列名一行
- index=False 不输出行索引一列
columns指定输出的列,传入列表
默认写入
1 | In [120]: d |
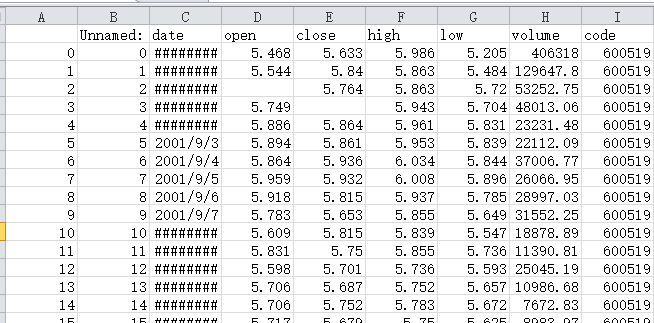
不输出行索引一列
1 | In [123]: d.to_csv('d0.csv', index=False) |
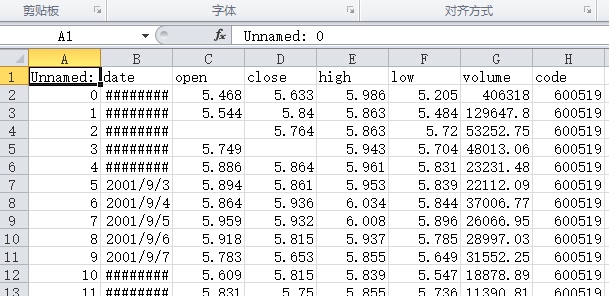
行列索引都不写入
1 | d.to_csv('d0.csv', index=False, header=False) |
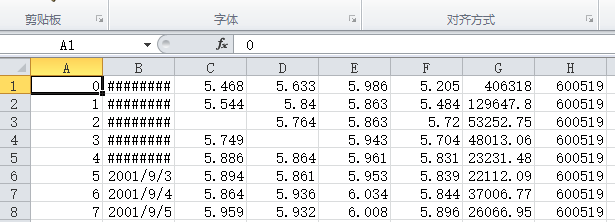
仅写入指定列
1 | d.to_csv('d0.csv', index=False, columns=['date', 'open']) |

使用指定字符串填充缺失值
1 | d.to_csv('d0.csv', index=False,columns=['date', 'open', 'close'], na_rep='None') |