Linux shell 基本命令
shell是操作系统中的一个软件,它包在 linux 内核的外面,为用户和内核之间的交互提供了一个接口,系统中的命令用 shell 去解释 shell 接收系统回应的输出并显示其到屏幕上;
可以将 Shell 终端解释器当作人与计算机硬件之间的“翻译官”它作为用户与 Linux 系统内部的通信媒介,除了能够支持各种变量与参数外,还提供了诸如循环、分支等高级编程语言才有的控制结构特性。
Linux命令行的组成结构
1 | [root@tony-PC:home/tony]# |
linux命令行操作语法格式
| 命令 | 空格 | 参数 | 空格 | 【文件或路径】需要处理的内容 |
|---|---|---|---|---|
rm |
-rf |
/tmp/* |
||
ls |
-la |
/home | ||
| 结婚 | -没车没房 | 女的就行 | ||
| 结婚 | -有车有房 | 白富美 |
1.一般情况下,【参数】是可选的,一些情况下【文件或路径】也是可选的
2.参数 > 同一个命令,跟上不同的参数执行不同的功能
执行linux命令,添加参数的目的是让命令更加贴切实际工作的需要!
linux命令,参数之间,普遍应该用一个或多个空格分割!
记录一组常用命令行:
1 | # 查询redis运行端口 |
常用命令行
创建目录
1 | make directory > mk dir > mkdir |
查看目录下文件
1 | #显示/media下的内容 |
切换目录/位置
1 | cd /home #切换到/home |
查看当前目录
1 | pwd |
创建文件并修改文件创建时间
1 | #修改文件的更改时间,很多黑客就会在恶意修改文件之后再修改成之前的时间 |
显示文件状态
stat命令用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细。
语法
1 | stat(选项)(参数) |
选项
1 | -L:支持符号连接; |
参数
文件:指定要显示信息的普通文件或者文件系统对应的设备文件名。
实例
1 | # 示例1: 显示文件信息 |
vim编辑器
所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在。
但是目前我们使用比较多的是 vim 编辑器。
vim 具有程序编辑的能力,可以主动的以字体颜色辨别语法的正确性,方便程序设计。
查看文件内容
cat命令用于查看纯文本文件(常用于内容较少的)
1 | #查看文件,显示行号 |
more查看文件内容
**more命令**是一个基于vi编辑器文本过滤器,它以全屏幕的方式按页显示文本文件的内容,支持vi中的关键字定位操作。more名单中内置了若干快捷键,常用的有H(获得帮助信息),Enter(向下翻滚一行),空格(向下滚动一屏),Q(退出命令)。
该命令一次显示一屏文本,满屏后停下来,并且在屏幕的底部出现一个提示信息,给出至今己显示的该文件的百分比:--More--(XX%)可以用下列不同的方法对提示做出回答:
- 按Space键:显示文本的下一屏内容。
- 按Enier键:只显示文本的下一行内容。
- 按斜线符|:接着输入一个模式,可以在文本中寻找下一个相匹配的模式。
- 按H键:显示帮助屏,该屏上有相关的帮助信息。
- 按B键:显示上一屏内容。
- 按Q键:退出
rnore命令。
语法
1 | more(语法)(参数) |
选项
1 | -<数字>:指定每屏显示的行数; |
参数
文件:指定分页显示内容的文件。
实例
显示文件file的内容,但在显示之前先清屏,并且在屏幕的最下方显示完核的百分比。
1 | more -dc file |
显示文件file的内容,每10行显示一次,而且在显示之前先清屏。
1 | more -c -10 file |
linux快捷键
1 | 1.tab键 用于自动补全命令/文件名/目录名 |
echo命令
echo命令用于在shell中打印shell变量的值,或者直接输出指定的字符串。linux的echo命令,在shell编程中极为常用, 在终端下打印变量value的时候也是常常用到的,因此有必要了解下echo的用法echo命令的功能是在显示器上显示一段文字,一般起到一个提示的作用。
语法
1 | echo(选项)(参数) |
选项
1 | -e:激活转义字符。 |
使用-e选项时,若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
- \a 发出警告声;
- \b 删除前一个字符;
- \c 最后不加上换行符号;
- \f 换行但光标仍旧停留在原来的位置;
- \n 换行且光标移至行首;
- \r 光标移至行首,但不换行;
- \t 插入tab;
- \v 与\f相同;
- \ 插入\字符;
\nnn插入nnn(八进制)所代表的ASCII字符;
参数
变量:指定要打印的变量。
实例
用echo命令打印带有色彩的文字:
文字色:
1 | echo -e "\e[1;31mThis is red text\e[0m" |
\e[1;31m将颜色设置为红色\e[0m将颜色重新置回
颜色码:重置=0,黑色=30,红色=31,绿色=32,黄色=33,蓝色=34,洋红=35,青色=36,白色=37
背景色:
1 | echo -e "\e[1;42mGreed Background\e[0m" |
颜色码:重置=0,黑色=40,红色=41,绿色=42,黄色=43,蓝色=44,洋红=45,青色=46,白色=47
文字闪动:
1 | echo -e "\033[37;31;5mMySQL Server Stop...\033[39;49;0m" |
红色数字处还有其他数字参数:0 关闭所有属性、1 设置高亮度(加粗)、4 下划线、5 闪烁、7 反显、8 消隐
使用echo将内容写入文件(会覆盖文件原有内容)
1 | #默认吧内容显示到终端上 |
特殊符号
1 | 输入/输出 重定向符号 |
复制命令
**cp命令**用来将一个或多个源文件或者目录复制到指定的目的文件或目录。它可以将单个源文件复制成一个指定文件名的具体的文件或一个已经存在的目录下。cp命令还支持同时复制多个文件,当一次复制多个文件时,目标文件参数必须是一个已经存在的目录,否则将出现错误。
语法
1 | cp(选项)(参数) |
选项
1 | -a:此参数的效果和同时指定"-dpR"参数相同; |
参数
- 源文件:制定源文件列表。默认情况下,cp命令不能复制目录,如果要复制目录,则必须使用
-R选项; - 目标文件:指定目标文件。当“源文件”为多个文件时,要求“目标文件”为指定的目录。
实例
如果把一个文件复制到一个目标文件中,而目标文件已经存在,那么,该目标文件的内容将被破坏。此命令中所有参数既可以是绝对路径名,也可以是相对路径名。通常会用到点.或点点..的形式。例如,下面的命令将指定文件复制到当前目录下:
1 | cp ../mary/homework/assign . |
所有目标文件指定的目录必须是己经存在的,cp命令不能创建目录。如果没有文件复制的权限,则系统会显示出错信息。
将文件file复制到目录/usr/men/tmp下,并改名为file1
1 | cp file /usr/men/tmp/file1 |
将目录/usr/men下的所有文件及其子目录复制到目录/usr/zh中
1 | cp -r /usr/men /usr/zh |
交互式地将目录/usr/men中的以m打头的所有.c文件复制到目录/usr/zh中
1 | cp -i /usr/men m*.c /usr/zh |
我们在Linux下使用cp命令复制文件时候,有时候会需要覆盖一些同名文件,覆盖文件的时候都会有提示:需要不停的按Y来确定执行覆盖。文件数量不多还好,但是要是几百个估计按Y都要吐血了,于是折腾来半天总结了一个方法:
1 | cp aaa/* /bbb |
移动命令
**mv命令**用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。source表示源文件或目录,target表示目标文件或目录。如果将一个文件移到一个已经存在的目标文件中,则目标文件的内容将被覆盖。
删除命令
**rm命令**可以删除一个目录中的一个或多个文件或目录,也可以将某个目录及其下属的所有文件及其子目录均删除掉。对于链接文件,只是删除整个链接文件,而原有文件保持不变。
查找命令
find命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
语法
1 | find(选项)(参数) |
选项
1 | -amin<分钟>:查找在指定时间曾被存取过的文件或目录,单位以分钟计算; |
参数
起始目录:查找文件的起始目录。
实例
根据文件或者正则表达式进行匹配
列出当前目录及子目录下所有文件和文件夹
1 | find . |
在/home目录下查找以.txt结尾的文件名
1 | find /home -name "*.txt" |
同上,但忽略大小写
1 | find /home -iname "*.txt" |
当前目录及子目录下查找所有以.txt和.pdf结尾的文件
1 | find . \( -name "*.txt" -o -name "*.pdf" \) |
匹配文件路径或者文件
1 | find /usr/ -path "*local*" |
基于正则表达式匹配文件路径
1 | find . -regex ".*\(\.txt\|\.pdf\)$" |
同上,但忽略大小写
1 | find . -iregex ".*\(\.txt\|\.pdf\)$" |
否定参数
找出/home下不是以.txt结尾的文件
1 | find /home ! -name "*.txt" |
根据文件类型进行搜索
1 | find . -type 类型参数 |
类型参数列表:
- f 普通文件
- l 符号连接
- d 目录
- c 字符设备
- b 块设备
- s 套接字
- p
Fifo
基于目录深度搜索
向下最大深度限制为3
1 | find . -maxdepth 3 -type f |
搜索出深度距离当前目录至少2个子目录的所有文件
1 | find . -mindepth 2 -type f |
根据文件时间戳进行搜索
1 | find . -type f 时间戳 |
UNIX/Linux文件系统每个文件都有三种时间戳:
- 访问时间(-atime/天,-amin/分钟):用户最近一次访问时间。
- 修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间。
- 变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
搜索最近七天内被访问过的所有文件
1 | find . -type f -atime -7 |
搜索恰好在七天前被访问过的所有文件
1 | find . -type f -atime 7 |
搜索超过七天内被访问过的所有文件
1 | find . -type f -atime +7 |
搜索访问时间超过10分钟的所有文件
1 | find . -type f -amin +10 |
找出比file.log修改时间更长的所有文件
1 | find . -type f -newer file.log |
根据文件大小进行匹配
1 | find . -type f -size 文件大小单元 |
文件大小单元:
- b —— 块(512字节)
- c —— 字节
- w —— 字(2字节)
- k —— 千字节
- M —— 兆字节
- G —— 吉字节
搜索大于10KB的文件
1 | find . -type f -size +10k |
搜索小于10KB的文件
1 | find . -type f -size -10k |
搜索等于10KB的文件
1 | find . -type f -size 10k |
删除匹配文件
删除当前目录下所有.txt文件
1 | find . -type f -name "*.txt" -delete |
根据文件权限/所有权进行匹配
当前目录下搜索出权限为777的文件
1 | find . -type f -perm 777 |
找出当前目录下权限不是644的php文件
1 | find . -type f -name "*.php" ! -perm 644 |
找出当前目录用户tom拥有的所有文件
1 | find . -type f -user tom |
找出当前目录用户组sunk拥有的所有文件
1 | find . -type f -group sunk |
借助-exec选项与其他命令结合使用
找出当前目录下所有root的文件,并把所有权更改为用户tom
1 | find .-type f -user root -exec chown tom {} \; |
上例中,{} 用于与**-exec**选项结合使用来匹配所有文件,然后会被替换为相应的文件名。
找出自己家目录下所有的.txt文件并删除
1 | find $HOME/. -name "*.txt" -ok rm {} \; |
上例中,-ok和**-exec**行为一样,不过它会给出提示,是否执行相应的操作。
查找当前目录下所有.txt文件并把他们拼接起来写入到all.txt文件中
1 | find . -type f -name "*.txt" -exec cat {} \;> all.txt |
将30天前的.log文件移动到old目录中
1 | find . -type f -mtime +30 -name "*.log" -exec cp {} old \; |
找出当前目录下所有.txt文件并以“File:文件名”的形式打印出来
1 | find . -type f -name "*.txt" -exec printf "File: %s\n" {} \; |
因为单行命令中-exec参数中无法使用多个命令,以下方法可以实现在-exec之后接受多条命令
1 | -exec ./text.sh {} \; |
搜索但跳出指定的目录
查找当前目录或者子目录下所有.txt文件,但是跳过子目录sk
1 | find . -path "./sk" -prune -o -name "*.txt" -print |
find其他技巧收集
要列出所有长度为零的文件
1 | find . -empty |
管道命令
1 | 复制代码 |
命令格式: 命令A | 命令B
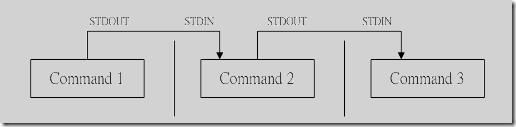
grep命令
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
选项
1 | -a 不要忽略二进制数据。 |
grep命令常见用法
在文件中搜索一个单词,命令会返回一个包含**“match_pattern”**的文本行:
1 | grep match_pattern file_name |
在多个文件中查找:
1 | grep "match_pattern" file_1 file_2 file_3 ... |
输出除之外的所有行 -v 选项:
1 | grep -v "match_pattern" file_name |
标记匹配颜色 –color=auto 选项:
1 | grep "match_pattern" file_name --color=auto |
使用正则表达式 -E 选项:
1 | grep -E "[1-9]+" |
只输出文件中匹配到的部分 -o 选项:
1 | echo this is a test line. | grep -o -E "[a-z]+\." |
统计文件或者文本中包含匹配字符串的行数 -c 选项:
1 | grep -c "text" file_name |
输出包含匹配字符串的行数 -n 选项:
1 | grep "text" -n file_name |
打印样式匹配所位于的字符或字节偏移:
1 | echo gun is not unix | grep -b -o "not" |
搜索多个文件并查找匹配文本在哪些文件中:
1 | grep -l "text" file1 file2 file3... |
grep递归搜索文件
在多级目录中对文本进行递归搜索:
1 | grep "text" . -r -n |
忽略匹配样式中的字符大小写:
1 | echo "hello world" | grep -i "HELLO" |
选项 -e 制动多个匹配样式:
1 | echo this is a text line | grep -e "is" -e "line" -o |
在grep搜索结果中包括或者排除指定文件:
1 | #只在目录中所有的.php和.html文件中递归搜索字符"main()" |
使用0值字节后缀的grep与xargs:
1 | #测试文件: |
grep静默输出:
1 | grep -q "test" filename |
打印出匹配文本之前或者之后的行:
1 | #显示匹配某个结果之后的3行,使用 -A 选项: |
常用实例
1 | grep "我要找什么" /tmp/hello.txt |
找出/etc/passwd下root用户所在行,以及行号,显示颜色
1 | cat /etc/passwd |grep '^root' --color=auto -n |
找出/etc/passwd所有不允许登录的用户
1 | grep /sbin/nologin /etc/passwd |
找到/etc/passwd的所有与mysql有关行,行号
1 | cat /etc/passwd |grep 'mysql' -n |
head命令
head命令用于显示文件的开头的内容。在默认情况下,head命令显示文件的头10行内容。
语法
1 | head(选项)(参数) |
选项
1 | -n<数字>:指定显示头部内容的行数; |
参数
文件列表:指定显示头部内容的文件列表。
tail命令
tail命令用于输入文件中的尾部内容。tail命令默认在屏幕上显示指定文件的末尾10行。如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。
注意:如果表示字节或行数的N值之前有一个”+”号,则从文件开头的第N项开始显示,而不是显示文件的最后N项。N值后面可以有后缀:b表示512,k表示1024,m表示1 048576(1M)。
语法
1 | tail(选项)(参数) |
选项
1 | --retry:即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项“——follow=name”连用; |
参数
文件列表:指定要显示尾部内容的文件列表。
实例
1 | tail file (显示文件file的最后10行) |
1 | # head显示文件前几行,默认前10行 |
sed
**sed**是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed的选项、命令、替换标记
命令格式
1 | sed [options] 'command' file(s) |
选项
1 | -e<script>或--expression=<script>:以选项中的指定的script来处理输入的文本文件; |
参数
文件:指定待处理的文本文件列表。
sed命令
1 | a\ 在当前行下面插入文本。 |
sed替换标记
1 | g 表示行内全面替换。 |
sed元字符集
1 | ^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。 |
sed用法实例
替换操作:s命令
替换文本中的字符串:
1 | sed 's/book/books/' file |
-n选项和p命令一起使用表示只打印那些发生替换的行:
sed -n ‘s/test/TEST/p’ file
直接编辑文件选项-i,会匹配file文件中每一行的第一个book替换为books:
1 | sed -i 's/book/books/g' file |
全面替换标记g
使用后缀 /g 标记会替换每一行中的所有匹配:
1 | sed 's/book/books/g' file |
当需要从第N处匹配开始替换时,可以使用 /Ng:
1 | echo sksksksksksk | sed 's/sk/SK/2g' |
定界符
以上命令中字符 / 在sed中作为定界符使用,也可以使用任意的定界符:
1 | sed 's:test:TEXT:g' |
定界符出现在样式内部时,需要进行转义:
1 | sed 's/\/bin/\/usr\/local\/bin/g' |
删除操作:d命令
删除空白行:
1 | sed '/^$/d' file |
删除文件的第2行:
1 | sed '2d' file |
删除文件的第2行到末尾所有行:
1 | sed '2,$d' file |
删除文件最后一行:
1 | sed '$d' file |
删除文件中所有开头是test的行:
1 | sed '/^test/'d file |
已匹配字符串标记&
正则表达式 \w+ 匹配每一个单词,使用 [&] 替换它,& 对应于之前所匹配到的单词:
1 | echo this is a test line | sed 's/\w\+/[&]/g' |
所有以192.168.0.1开头的行都会被替换成它自已加localhost:
1 | sed 's/^192.168.0.1/&localhost/' file |
子串匹配标记\1
匹配给定样式的其中一部分:
1 | echo this is digit 7 in a number | sed 's/digit \([0-9]\)/\1/' |
命令中 digit 7,被替换成了 7。样式匹配到的子串是 7,(..) 用于匹配子串,对于匹配到的第一个子串就标记为 \1,依此类推匹配到的第二个结果就是 \2,例如:
1 | echo aaa BBB | sed 's/\([a-z]\+\) \([A-Z]\+\)/\2 \1/' |
love被标记为1,所有loveable会被替换成lovers,并打印出来:
1 | sed -n 's/\(love\)able/\1rs/p' file |
组合多个表达式
1 | sed '表达式' | sed '表达式' |
引用
sed表达式可以使用单引号来引用,但是如果表达式内部包含变量字符串,就需要使用双引号。
1 | test=hello |
选定行的范围:,(逗号)
所有在模板test和check所确定的范围内的行都被打印:
1 | sed -n '/test/,/check/p' file |
打印从第5行开始到第一个包含以test开始的行之间的所有行:
1 | sed -n '5,/^test/p' file |
对于模板test和west之间的行,每行的末尾用字符串aaa bbb替换:
1 | sed '/test/,/west/s/$/aaa bbb/' file |
多点编辑:e命令
-e选项允许在同一行里执行多条命令:
1 | sed -e '1,5d' -e 's/test/check/' file |
上面sed表达式的第一条命令删除1至5行,第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
和 -e 等价的命令是 –expression:
1 | sed --expression='s/test/check/' --expression='/love/d' file |
从文件读入:r命令
file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面:
1 | sed '/test/r file' filename |
写入文件:w命令
在example中所有包含test的行都被写入file里:
1 | sed -n '/test/w file' example |
追加(行下):a\命令
将 this is a test line 追加到 以test 开头的行后面:
1 | sed '/^test/a\this is a test line' file |
在 test.conf 文件第2行之后插入 this is a test line:
1 | sed -i '2a\this is a test line' test.conf |
插入(行上):i\命令
将 this is a test line 追加到以test开头的行前面:
1 | sed '/^test/i\this is a test line' file |
在test.conf文件第5行之前插入this is a test line:
1 | sed -i '5i\this is a test line' test.conf |
下一个:n命令
如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续:
1 | sed '/test/{ n; s/aa/bb/; }' file |
变形:y命令
把1~10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令:
1 | sed '1,10y/abcde/ABCDE/' file |
退出:q命令
打印完第10行后,退出sed
1 | sed '10q' file |
保持和获取:h命令和G命令
在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。
1 | sed -e '/test/h' -e '$G' file |
在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
保持和互换:h命令和x命令
互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换:
1 | sed -e '/test/h' -e '/check/x' file |
脚本scriptfile
sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
1 | sed [options] -f scriptfile file(s) |
打印奇数行或偶数行
方法1:
1 | sed -n 'p;n' test.txt #奇数行 |
方法2:
1 | sed -n '1~2p' test.txt #奇数行 |
打印匹配字符串的下一行
1 | grep -A 1 SCC URFILE |
别名alias命令
alias命令用来设置指令的别名。我们可以使用该命令可以将一些较长的命令进行简化。使用alias时,用户必须使用单引号''将原来的命令引起来,防止特殊字符导致错误。
alias命令的作用只局限于该次登入的操作。若要每次登入都能够使用这些命令别名,则可将相应的alias命令存放到bash的初始化文件/etc/bashrc中。
语法
1 | alias(选项)(参数) |
选项
1 | -p:打印已经设置的命令别名。 |
参数
命令别名设置:定义命令别名,格式为“命令别名=‘实际命令’”。
实例
alias 的基本使用方法为:
1 | alias 新的命令='原命令 -选项/参数' |
例如:alias l=‘ls -lsh'将重新定义ls命令,现在只需输入l就可以列目录了。直接输入 alias 命令会列出当前系统中所有已经定义的命令别名。
要删除一个别名,可以使用 unalias 命令,如 unalias l。
查看系统已经设置的别名:
1 | alias -p |
1 | Linux如何提示你,在使用这些命令时候,提醒你小心呢? |
为rm设置别名
1 | #让系统显示 do not use rm |
which命令
which命令用于查找并显示给定命令的绝对路径,环境变量PATH中保存了查找命令时需要遍历的目录。which指令会在环境变量$PATH设置的目录里查找符合条件的文件。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
语法
1 | which(选项)(参数) |
选项
1 | -n<文件名长度>:制定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名; |
参数
指令名:指令名列表。
实例
查找文件、显示命令路径:
1 | [root@localhost ~]# which pwd |
说明:which是根据使用者所配置的 PATH 变量内的目录去搜寻可运行档的!所以,不同的 PATH 配置内容所找到的命令当然不一样的!
scp命令
scp命令用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可能会稍微影响一下速度。当你服务器硬盘变为只读read only system时,用scp可以帮你把文件移出来。另外,scp还非常不占资源,不会提高多少系统负荷,在这一点上,rsync就远远不及它了。虽然 rsync比scp会快一点,但当小文件众多的情况下,rsync会导致硬盘I/O非常高,而scp基本不影响系统正常使用。
语法
1 | scp(选项)(参数) |
选项
1 | -1:使用ssh协议版本1; |
参数
- 源文件:指定要复制的源文件。
- 目标文件:目标文件。格式为
user@host:filename(文件名为目标文件的名称)。
实例
从远程复制到本地的scp命令与上面的命令雷同,只要将从本地复制到远程的命令后面2个参数互换顺序就行了。
从远处复制文件到本地目录
1 | scp root@10.10.10.10:/opt/soft/nginx-0.5.38.tar.gz /opt/soft/ |
从10.10.10.10机器上的/opt/soft/的目录中下载nginx-0.5.38.tar.gz 文件到本地/opt/soft/目录中。
从远处复制到本地
1 | scp -r root@10.10.10.10:/opt/soft/mongodb /opt/soft/ |
从10.10.10.10机器上的/opt/soft/中下载mongodb目录到本地的/opt/soft/目录来。
上传本地文件到远程机器指定目录
1 | scp /opt/soft/nginx-0.5.38.tar.gz root@10.10.10.10:/opt/soft/scptest |
复制本地/opt/soft/目录下的文件nginx-0.5.38.tar.gz到远程机器10.10.10.10的opt/soft/scptest目录。
上传本地目录到远程机器指定目录
1 | scp -r /opt/soft/mongodb root@10.10.10.10:/opt/soft/scptest |
上传本地目录/opt/soft/mongodb到远程机器10.10.10.10上/opt/soft/scptest的目录中去。
du命令
du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的。
语法
1 | du [选项][文件] |
选项
1 | -a或-all 显示目录中个别文件的大小。 |
实例
显示目录或者文件所占空间:
1 | [root@localhost test]# du |
只显示当前目录下面的子目录的目录大小和当前目录的总的大小,最下面的1288为当前目录的总大小
显示指定文件所占空间:
1 | [root@localhost test]# du log2012.log |
查看指定目录的所占空间:
1 | [root@localhost test]# du scf |
显示多个文件所占空间:
1 | [root@localhost test]# du log30.tar.gz log31.tar.gz |
只显示总和的大小:
1 | [root@localhost test]# du -s |
1 | #显示/home的总大小 |
top命令
top命令可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。通过top命令所提供的互动式界面,用热键可以管理。
语法
1 | top(选项) |
选项
1 | -b:以批处理模式操作; |
top交互命令
在top命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了-s选项, 其中一些命令可能会被屏蔽。
1 | h:显示帮助画面,给出一些简短的命令总结说明; |
实例
1 | top - 09:44:56 up 16 days, 21:23, 1 user, load average: 9.59, 4.75, 1.92 |
解释:
- top - 09:44:56[当前系统时间],
- 16 days[系统已经运行了16天],
- 1 user[个用户当前登录],
- load average: 9.59, 4.75, 1.92[系统负载,即任务队列的平均长度]
- Tasks: 145 total[总进程数],
- 2 running[正在运行的进程数],
- 143 sleeping[睡眠的进程数],
- 0 stopped[停止的进程数],
- 0 zombie[冻结进程数],
- Cpu(s): 99.8%us[用户空间占用CPU百分比],
- 0.1%sy[内核空间占用CPU百分比],
- 0.0%ni[用户进程空间内改变过优先级的进程占用CPU百分比],
- 0.2%id[空闲CPU百分比], 0.0%wa[等待输入输出的CPU时间百分比],
- 0.0%hi[],
- 0.0%st[],
- Mem: 4147888k total[物理内存总量],
- 2493092k used[使用的物理内存总量],
- 1654796k free[空闲内存总量],
- 158188k buffers[用作内核缓存的内存量]
- Swap: 5144568k total[交换区总量],
- 56k used[使用的交换区总量],
- 5144512k free[空闲交换区总量],
2013180kcached[缓冲的交换区总量],
chattr命令
chattr命令用来改变文件属性。这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式:
1 | a:让文件或目录仅供附加用途; |
语法
1 | chattr(选项) |
选项
1 | -R:递归处理,将指令目录下的所有文件及子目录一并处理; |
实例
用chattr命令防止系统中某个关键文件被修改:
1 | chattr +i /etc/fstab |
然后试一下rm、mv、rename等命令操作于该文件,都是得到Operation not permitted的结果。
让某个文件只能往里面追加内容,不能删除,一些日志文件适用于这种操作:
1 | chattr +a /data1/user_act.log |
给文件加锁,只能写入数据,无法删除文件
1 | chattr +a test.py |
lsattr命令
lsattr命令用于查看文件的第二扩展文件系统属性。
语法
1 | lsattr(选项)(参数) |
选项
1 | -E:可显示设备属性的当前值,但这个当前值是从用户设备数据库中获得的,而不是从设备直接获得的。 |
lsattr经常使用的几个选项-D,-E,-R这三个选项不可以一起使用,它们是互斥的,经常使用的还有-l,-H,使用lsattr时,必须指出具体的设备名,用-l选项指出要显示设备的逻辑名称,否则要用-c,-s,-t等选项唯一的确定某个已存在的设备。
参数
文件:指定显示文件系统属性的文件名。
实例
1 | lsattr -E -l rmt0 -H |
查看文件隐藏属性
1 | lsattr test.py |
wget命令
wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
语法
1 | wget(选项)(参数) |
选项
1 | -a<日志文件>:在指定的日志文件中记录资料的执行过程; |
参数
URL:下载指定的URL地址。
实例
使用wget下载单个文件
1 | wget http://www.linuxde.net/testfile.zip |
以下的例子是从网络下载一个文件并保存在当前目录,在下载的过程中会显示进度条,包含(下载完成百分比,已经下载的字节,当前下载速度,剩余下载时间)。
下载并以不同的文件名保存
1 | wget -O wordpress.zip http://www.linuxde.net/download.aspx?id=1080 |
wget默认会以最后一个符合/的后面的字符来命令,对于动态链接的下载通常文件名会不正确。
错误:下面的例子会下载一个文件并以名称download.aspx?id=1080保存:
1 | wget http://www.linuxde.net/download?id=1 |
即使下载的文件是zip格式,它仍然以download.php?id=1080命令。
正确:为了解决这个问题,我们可以使用参数-O来指定一个文件名:
1 | wget -O wordpress.zip http://www.linuxde.net/download.aspx?id=1080 |
wget限速下载
1 | wget --limit-rate=300k http://www.linuxde.net/testfile.zip |
当你执行wget的时候,它默认会占用全部可能的宽带下载。但是当你准备下载一个大文件,而你还需要下载其它文件时就有必要限速了。
使用wget断点续传
1 | wget -c http://www.linuxde.net/testfile.zip |
使用wget -c重新启动下载中断的文件,对于我们下载大文件时突然由于网络等原因中断非常有帮助,我们可以继续接着下载而不是重新下载一个文件。需要继续中断的下载时可以使用-c参数。
使用wget后台下载
1 | wget -b http://www.linuxde.net/testfile.zip |
对于下载非常大的文件的时候,我们可以使用参数-b进行后台下载,你可以使用以下命令来察看下载进度:
1 | tail -f wget-log |
伪装代理名称下载
1 | wget --user-agent="Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.204 Safari/534.16" http://www.linuxde.net/testfile.zip |
有些网站能通过根据判断代理名称不是浏览器而拒绝你的下载请求。不过你可以通过--user-agent参数伪装。
测试下载链接
当你打算进行定时下载,你应该在预定时间测试下载链接是否有效。我们可以增加--spider参数进行检查。
1 | wget --spider URL |
如果下载链接正确,将会显示:
1 | Spider mode enabled. Check if remote file exists. |
这保证了下载能在预定的时间进行,但当你给错了一个链接,将会显示如下错误:
1 | wget --spider url |
你可以在以下几种情况下使用--spider参数:
- 定时下载之前进行检查
- 间隔检测网站是否可用
- 检查网站页面的死链接
增加重试次数
1 | wget --tries=40 URL |
如果网络有问题或下载一个大文件也有可能失败。wget默认重试20次连接下载文件。如果需要,你可以使用--tries增加重试次数。
下载多个文件
1 | wget -i filelist.txt |
首先,保存一份下载链接文件:
1 | cat > filelist.txt |
接着使用这个文件和参数-i下载。
镜像网站
1 | wget --mirror -p --convert-links -P ./LOCAL URL |
下载整个网站到本地。
--miror开户镜像下载。-p下载所有为了html页面显示正常的文件。--convert-links下载后,转换成本地的链接。-P ./LOCAL保存所有文件和目录到本地指定目录。
过滤指定格式下载
1 | wget --reject=gif ur |
下载一个网站,但你不希望下载图片,可以使用这条命令。
把下载信息存入日志文件
1 | wget -o download.log URL |
不希望下载信息直接显示在终端而是在一个日志文件,可以使用。
限制总下载文件大小
1 | wget -Q5m -i filelist.txt |
当你想要下载的文件超过5M而退出下载,你可以使用。注意:这个参数对单个文件下载不起作用,只能递归下载时才有效。
下载指定格式文件
1 | wget -r -A.pdf url |
可以在以下情况使用该功能:
- 下载一个网站的所有图片。
- 下载一个网站的所有视频。
- 下载一个网站的所有PDF文件。
FTP下载
1 | wget ftp-url |
可以使用wget来完成ftp链接的下载。
使用wget匿名ftp下载:
1 | wget ftp-url |
使用wget用户名和密码认证的ftp下载:
1 | wget --ftp-user=USERNAME --ftp-password=PASSWORD url |
开关机命令
reboot
reboot命令用来重新启动正在运行的Linux操作系统。
语法
1 | reboot(选项) |
选项
1 | -d:重新开机时不把数据写入记录文件/var/tmp/wtmp。本参数具有“-n”参数效果; |
实例
1 | reboot //重开机。 |
poweroff
poweroff命令用来关闭计算机操作系统并且切断系统电源。
语法
1 | poweroff(选项) |
选项
1 | -n:关闭操作系统时不执行sync操作; |
实例
如果确认系统中已经没有用户存在且所有数据都已保存,需要立即关闭系统,可以使用poweroff命令。
使用poweroff立即关闭系统:
1 | poweroff |