Django REST Framework系列
DRF(Django RestFramework)是一套基于Django开发的、帮助我们更好的设计符合REST规范的Web应用的一个Django App,所以,本质上,它是一个Django App。

Django REST Framework系列文章
- 手摸手,带你用Django REST Framework撸接口系列一(基础篇)
- 手摸手,带你用Django REST Framework撸接口系列二(序列化器篇)
- 手摸手,带你用Django REST Framework撸接口系列三(视图篇)
- 手摸手,带你用Django REST Framework撸接口系列四(渲染器篇)
- 手摸手,带你用Django REST Framework撸接口系列五(路由篇)
- 手摸手,带你用Django REST Framework撸接口系列六(认证篇)
- 手摸手,带你用Django REST Framework撸接口系列七(权限篇)
- 手摸手,带你用Django REST Framework撸接口系列八(限流篇)
- 手摸手,带你用Django REST Framework撸接口系列九(过滤篇)
- 手摸手,带你用Django REST Framework撸接口系列十(排序篇)
- 手摸手,带你用Django REST Framework撸接口系列十一(分页篇)
- 手摸手,带你用Django REST Framework撸接口系列十二(异常处理篇)
- 手摸手,带你用Django REST Framework撸接口系列十三(自动生成接口文档篇)
认识Django RestFramework
本文先从以下几个方面逐步了解为什么要用Django RestFramework,关于它的官方文档,英文不好的同学也给你准备了中文文档
Web应用模式
在日常web应用开发中有两种应用模式:前后端不分离;前后端分离。
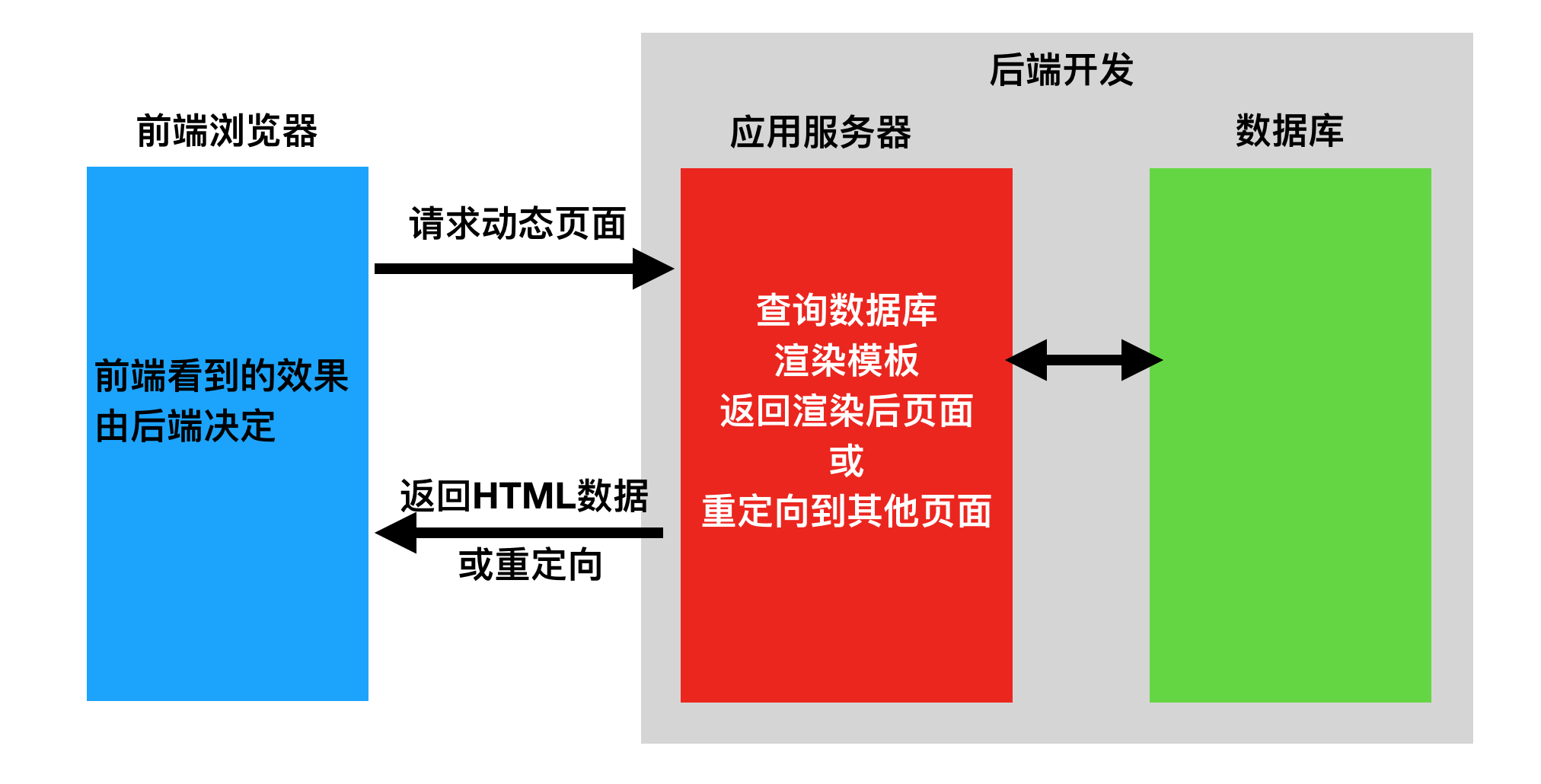
前后端不分离
在前后端不分离的应用模式中,前端页面看到的效果都是由后端控制,由后端渲染页面或重定向,也就是后端需要控制前端的展示,前端与后端的耦合度很高。
这种应用模式比较适合纯网页应用,但是当后端对接App时,App可能并不需要后端返回一个HTML网页,而仅仅是数据本身,所以后端原本返回网页的接口不再适用于前端App应用,为了对接App后端还需再开发一套接口。
前后端分离
在前后端分离的应用模式中,后端仅返回前端所需的数据,不再渲染HTML页面,不再控制前端的效果。至于前端用户看到什么效果,从后端请求的数据如何加载到前端中,都由前端自己决定,网页有网页的处理方式,App有App的处理方式,但无论哪种前端,所需的数据基本相同,后端仅需开发一套逻辑对外提供数据即可。
在前后端分离的应用模式中 ,前端与后端的耦合度相对较低。
在前后端分离的应用模式中,我们通常将后端开发的每个视图都称为一个接口,或者API,前端通过访问接口来对数据进行增删改查。

认识RESTful
RESTFUL是一种网络应用程序的设计风格和开发方式,基于HTTP,可以使用XML格式定义或JSON格式定义。RESTFUL适用于移动互联网厂商作为业务接口的场景,实现第三方OTT调用移动网络资源的功能,动作类型为新增、变更、删除所调用资源。
例如对于后端数据库中保存了文章的信息,前端可能需要对文章数据进行增删改查,那相应的每个操作后端都需要提供一个API接口:
1 | POST /add-article 添加文章 |
对于接口的请求方式与路径,每个后端开发人员可能都有自己的定义方式,风格迥异。是否存在一种统一的定义方式,被广大开发人员接受认可的方式呢?这就是被普遍采用的API的RESTful设计风格。
RESTful设计方法
域名
推荐应该尽量将api部署在专用域名下,如:https://api.diandian100.cn。
如果你的api很简单,不会考虑进一步进行扩展,也可以考虑放在主域名下,如:https://diandian100.cn/api/。
版本(Version)
除了域名设计,还应该将api的版本号放在url中如:https://api.diandian100.cn/1.0/article 或者https://diandian100.cn/api/1.0/article 。
另外还有一种做法是将版本号放入http头信息中,随访没有放入url中方便和直观,但是现在大多数网站还是采用了将版本号放入在了头部信息中,这样简化了url复杂度,个人也建议采用这种方式。
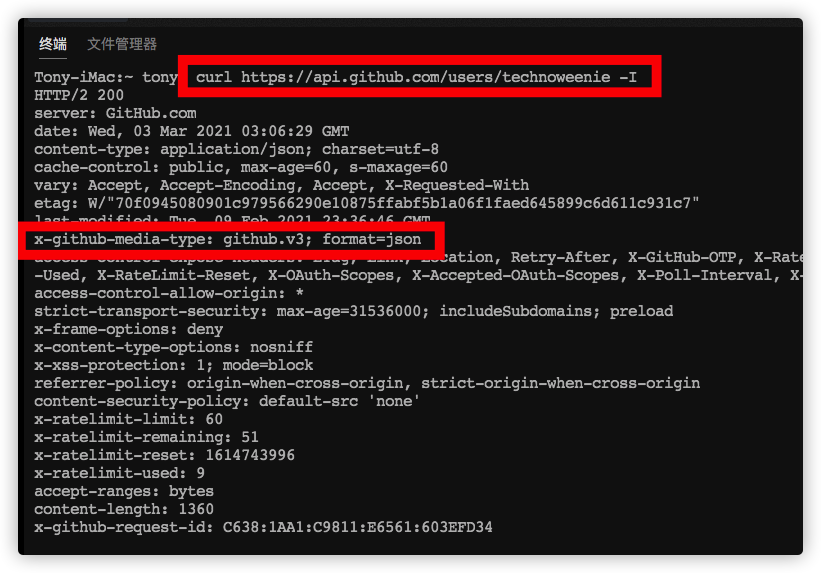
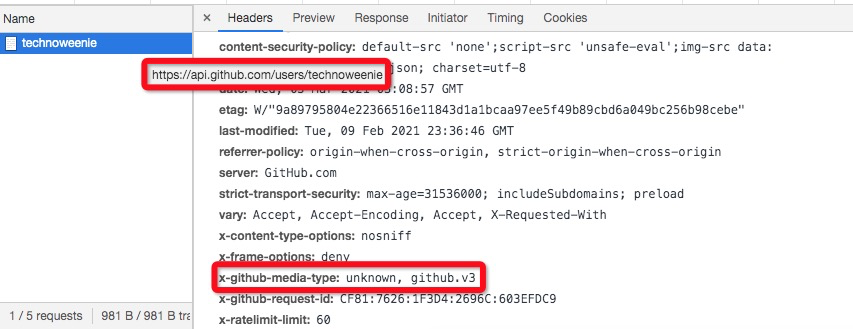
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URL。版本号可以在HTTP请求头信息的Accept字段中进行区分,这里以github为例:
1 | Accept: application/vnd.github.v3+json |
浏览器中也可以看出来
路径(Endpoint)
路径又称终点(endpoint),标识api的具体网址,每个网址代表一种资源(resource)
资源作为网址,只能有名词,不能有动词,而且所用的名词往往与数据库的表名对应
举例来说,以下就被认为是不好的例子
1
2
3/getArticles
/listArticles
/editArticle?id=1对于一个简洁结构,应该尽量使用名词。此外,利用的http方法可以分离网址中的资源名称的操作。
1
2
3
4
5GET /articles # 查询所有文章
POST /articles # 添加文章
GET /articles/2 # 查询id为2的文章
PUT /aritcles/2 # 更新id为2的文章
DELETE /articles/2 # 删除id为2的文章api中的名词应该使用复数,无论子资源或者所有资源
举例来说,获取文章的api可以这样定义
1
2https://api.diandian100.cn/AppName/articles/2 # 获取单个文章
https://api.diandian100.cn/AppName/articles # 获取所有文章
HTTP动词
对于资源的具体操作类型,由http动词表示,常用的http动词有下面4个(括号里对应的是sql命令)。
1 | GET(SELECT) # 从服务器取出资源(1个或多个) |
除了以上还有几个不常用的http动词
1 | OPTIONS # 获取信息,关于资源的哪些属性是客户端可以改变的 |
以下举例说明:
1 | GET /articles:列出所有文章 |
过滤信息(Filter)
如果返回记录数量很多,服务器不可能都将他们返回给用户,api应该提供参数,过滤返回的结果。如以下常见示例过滤参数:
1 | ?limit=10 # 指定返回记录的数量 |
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoos/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
状态码(Status Codes)
服务器向用户返回的状态码和提示信息,常见的有以下一些(括号中是该状态吗对应的http动词)
1 | 200 OK - [GET] # 服务器成功返回用户请求的数据 |
更详细的状态码说明参考:https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
错误处理(Error handling)
如果状态码是4xx,服务器就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
1 | { |
返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
1 | GET /collection # 返回资源对象的列表(数组) |
其他
服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
使用Django开发REST接口
我们以在Django框架中使用的图书英雄案例来写一套支持图书数据增删改查的REST API接口,来理解REST API的开发。
在此案例中,前后端均发送JSON格式数据。
1 | # views.py |
访问测试
使用Postman测试上述接口
1) 获取所有图书数据
GET 方式访问 http://127.0.0.1:8000/books/, 返回状态码200,数据如下
1 | [ |
2)获取单一图书数据
GET 访问 http://127.0.0.1:8000/books/5/ ,返回状态码200, 数据如下
1 | { |
GET 访问http://127.0.0.1:8000/books/100/,返回状态码404
3)新增图书数据
POST 访问http://127.0.0.1:8000/books/,发送JSON数据:
1 | { |
返回状态码201,数据如下
1 | { |
4)修改图书数据
PUT 访问http://127.0.0.1:8000/books/8/,发送JSON数据:
1 | { |
返回状态码200,数据如下
1 | { |
5)删除图书数据
DELETE 访问http://127.0.0.1:8000/books/8/,返回204状态码
剖析REST接口开发核心任务
从上面示例中可以发现,我们在开发REST API时,视图主要做了3件事:将请求的数据(如json格式)转换为模型类对象->操作数据库->将模型类对象转换为响应的数据(如json格式)
序列化Serialization
序列化(serialization)在计算机科学的资料处理中,是指将数据结构或物件状态转换成可取用格式(例如存成档案,存于缓冲,或经由网络中传送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始物件相同语义的副本。对于许多物件,像是使用大量参照的复杂物件,这种序列化重建的过程并不容易。面向对象中的物件序列化,并不概括之前原始物件所关联的函式。这种过程也称为物件编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组, deserialization, unmarshalling)。
序列化在计算机科学中通常有以下定义:
在数据储存与传送的部分是指将一个对象)存储至一个储存媒介,例如档案或是记亿体缓冲等,或者透过网络传送资料时进行编码的过程,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象)。这程序被应用在不同应用程序之间传送对象),以及服务器将对象)储存到档案或数据库。相反的过程又称为反序列化。
简而言之,我们可以将序列化理解为:
将程序中的一个数据结构类型转换为其他格式(字典、JSON、XML等),例如将Django中的模型类对象装换为JSON字符串,这个转换过程我们称为序列化。
如
1 | queryset = BookInfo.objects.all() |
反序列化
将其他格式(字典、JSON、XML等)转换为程序中的数据,例如将JSON字符串转换为Django中的模型类对象,这个过程我们称为反序列化。
如:
1 | json_bytes = request.body |
总结
从以上示例可以看出来,在开发REST API时,视图中要频繁的进行序列化与反序列化的编写。在开发REST API接口时,我们在视图**中需要做的最核心的事是:
- 将数据库数据序列化为前端所需要的格式,并返回;
- 将前端发送的数据反序列化为模型类对象,并保存到数据库中。
这便引出了我们的主角:Django REST Framework,它其中很重要的一部分功能实际上就是帮我们简化序列化和反序列化的事情的。
Django REST Framework简介
在序列化与反序列化时,虽然操作的数据不尽相同,但是执行的过程却是相似的,也就是说这部分代码是可以复用简化编写的。
在开发REST API的视图中,虽然每个视图具体操作的数据不同,但增、删、改、查的实现流程基本套路化,所以这部分代码也是可以复用简化编写的:
- 增:校验请求数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
- 删:判断要删除的数据是否存在 -> 执行数据库删除
- 改:判断要修改的数据是否存在 -> 校验请求的数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
- 查:查询数据库 -> 将数据序列化并返回
Django REST framework可以帮助我们简化上述两部分的代码编写,大大提高REST API的开发速度。
特点
Django REST framework 框架是一个用于构建Web API 的强大而又灵活的工具。通常简称为DRF框架 或 REST framework。
DRF框架是建立在Django框架基础之上,由Tom Christie大牛二次开发的开源项目。它有以下特点:
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
- 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
- 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
- 多种身份认证和权限认证方式的支持;
- 内置了限流系统;
- 直观的 API web 界面;
- 可扩展性,插件丰富
DRF安装与配置
DRF需要以下依赖:
Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6)Django (1.10, 1.11, 2.0)
DRF是以Django扩展应用的方式提供的,所以我们可以直接利用已有的Django环境而无需从新创建。(若没有Django环境,需要先创建环境安装Django)
安装DRF
1 | pip install djangorestframework |
添加rest_framework应用
我们利用在Django框架学习中创建的demo工程,在settings.py的INSTALLED_APPS中添加’rest_framework’。
1 | INSTALLED_APPS = [ |
接下来就可以使用DRF进行开发了。
Django REST Framework系列文章
- 手摸手,带你用Django REST Framework撸接口系列一(基础篇)
- 手摸手,带你用Django REST Framework撸接口系列二(序列化器篇)
- 手摸手,带你用Django REST Framework撸接口系列三(视图篇)
- 手摸手,带你用Django REST Framework撸接口系列四(渲染器篇)
- 手摸手,带你用Django REST Framework撸接口系列五(路由篇)
- 手摸手,带你用Django REST Framework撸接口系列六(认证篇)
- 手摸手,带你用Django REST Framework撸接口系列七(权限篇)
- 手摸手,带你用Django REST Framework撸接口系列八(限流篇)
- 手摸手,带你用Django REST Framework撸接口系列九(过滤篇)
- 手摸手,带你用Django REST Framework撸接口系列十(排序篇)
- 手摸手,带你用Django REST Framework撸接口系列十一(分页篇)
- 手摸手,带你用Django REST Framework撸接口系列十二(异常处理篇)
- 手摸手,带你用Django REST Framework撸接口系列十三(自动生成接口文档篇)